50b8c16d9ba62-thumb.jpg (11.89 KB, 下载次数: 254)
下载附件 保存到相册
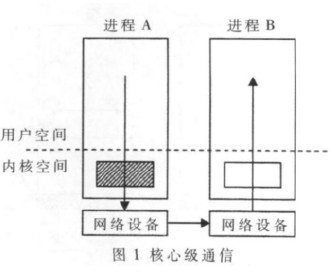
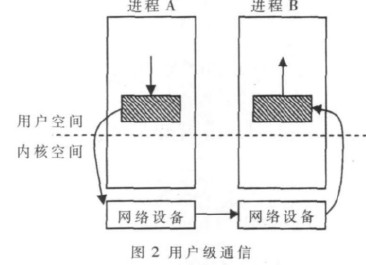
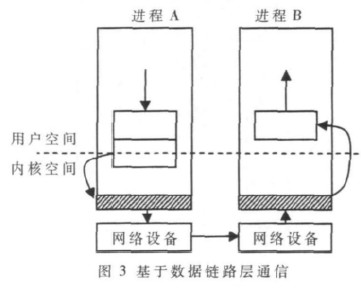
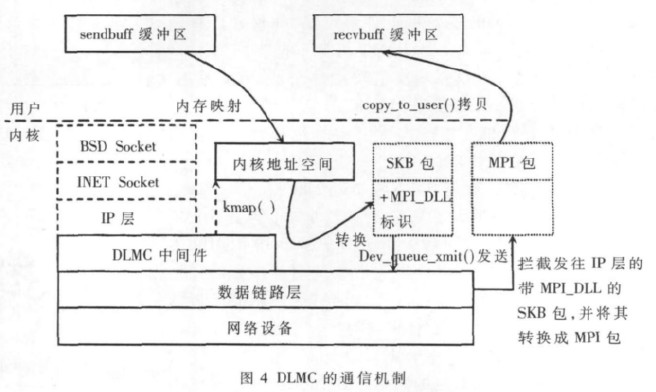
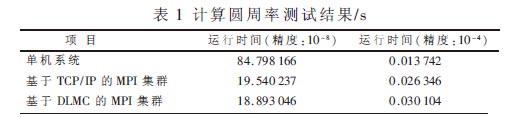
基于Linux数据链路层的MPI集群通信机制的设计与实现
2014-10-10 07:53 上传
50b8c16da1313-thumb.jpg (13.08 KB, 下载次数: 251)
50b8c16da49c2-thumb.jpg (14.52 KB, 下载次数: 246)
50b8c16da9b4b-thumb.jpg (23.05 KB, 下载次数: 243)
50b8c16dac643-thumb.jpg (12.05 KB, 下载次数: 247)
50b8c16dafe28-thumb.jpg (11.52 KB, 下载次数: 252)