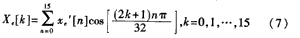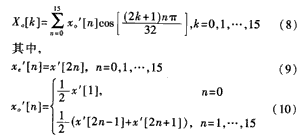50b8c10dcf340-thumb.gif (2.74 KB, 下载次数: 261)
下载附件 保存到相册
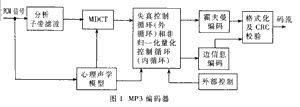
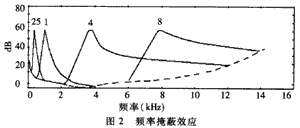
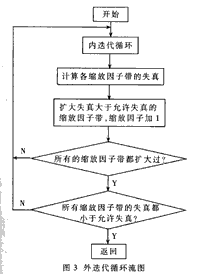
基于定点DSP的MP3音频编码算法研究
2014-10-10 08:04 上传
50b8c10dd1876-thumb.gif (2.77 KB, 下载次数: 274)
50b8c10dd5dfe-thumb.gif (5.62 KB, 下载次数: 265)
50b8c10ddaa45-thumb.gif (1.09 KB, 下载次数: 280)
50b8c10ddadb3-thumb.gif (2.7 KB, 下载次数: 268)
50b8c10dd5b36-thumb.gif (3.9 KB, 下载次数: 268)
50b8c10ddd8f8-thumb.gif (1.82 KB, 下载次数: 286)