50b8c0ccf3fd7-thumb.gif (20.39 KB, 下载次数: 239)
下载附件 保存到相册
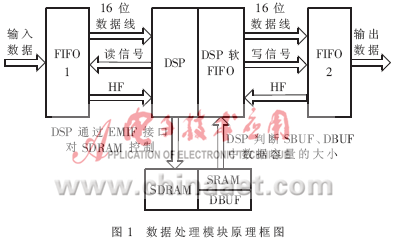
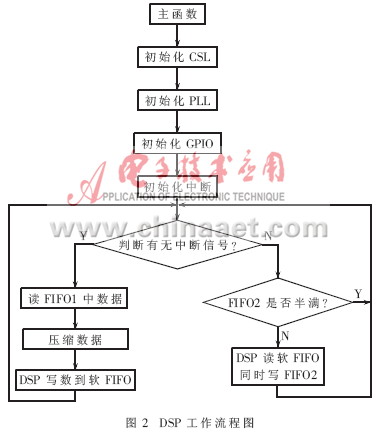
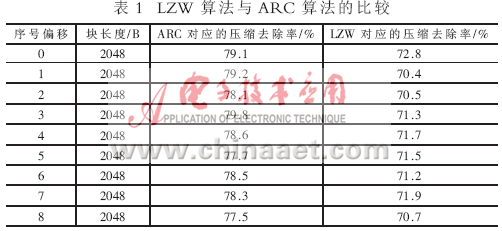
基于DSP的实时数据无损压缩实现方案
2014-10-10 08:13 上传
50b8c0cd03f5f-thumb.gif (19.59 KB, 下载次数: 240)
50b8c0cd0878b-thumb.gif (20.95 KB, 下载次数: 252)