50b8c0c813d2b-thumb.gif (19.7 KB, 下载次数: 217)
下载附件 保存到相册
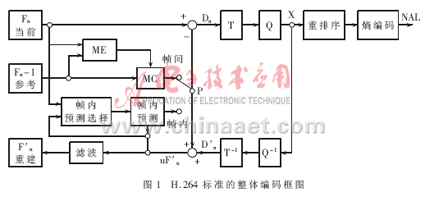
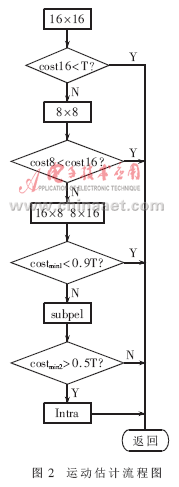
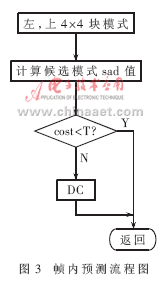
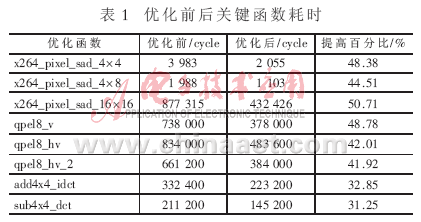
在ADSP-BF561上实现与优化的H.264
2014-10-10 08:13 上传
50b8c0c817580-thumb.gif (8.74 KB, 下载次数: 228)
50b8c0c819926-thumb.gif (7.74 KB, 下载次数: 235)
50b8c0c81d9b6-thumb.gif (33.33 KB, 下载次数: 231)
50b8c0c823f6d-thumb.gif (18.13 KB, 下载次数: 236)
50b8c0c826acc-thumb.gif (14.91 KB, 下载次数: 228)
50b8c0c828adb-thumb.gif (9.31 KB, 下载次数: 229)