50bb4511bf394-thumb.gif (18.55 KB, 下载次数: 167)
下载附件 保存到相册
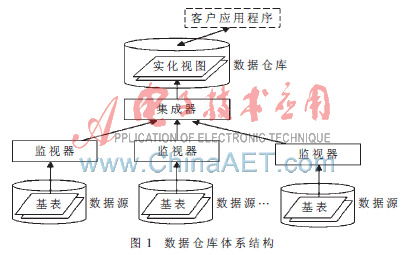
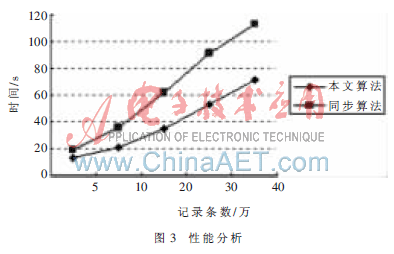
流水线处理技术在数据集成中的应用
2014-10-10 08:49 上传
50bb4511c62d8-thumb.gif (14.84 KB, 下载次数: 176)
50bb4511c6980-thumb.gif (28.37 KB, 下载次数: 174)