51bac8fa015d6-thumb.jpg (19.9 KB, 下载次数: 117)
下载附件 保存到相册
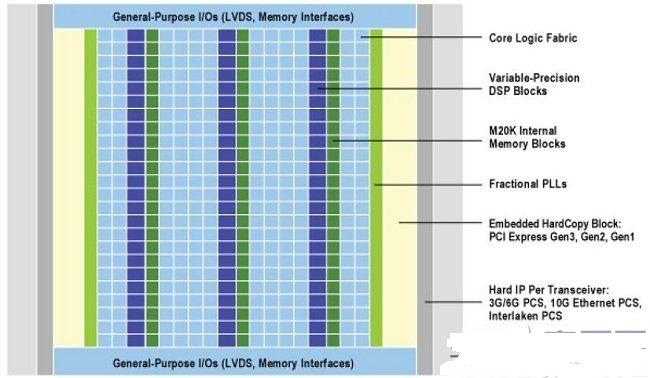
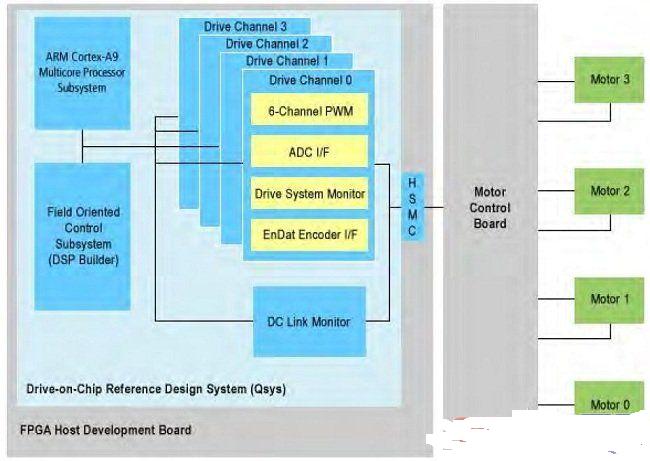
如何选择满足FPGA设计需求的工艺?
2014-10-13 17:46 上传
51bac8fbb01d1-thumb.jpg (25.97 KB, 下载次数: 116)
51bac954a6889-thumb.jpg (25.37 KB, 下载次数: 119)