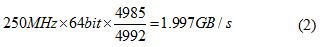548ab3e9d053e-thumb.jpg (21.39 KB, 下载次数: 134)
下载附件 保存到相册
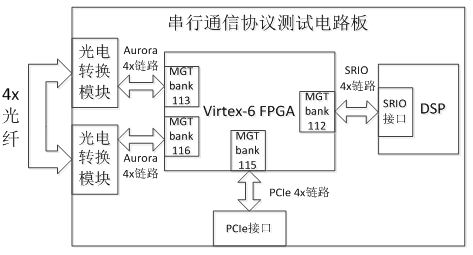
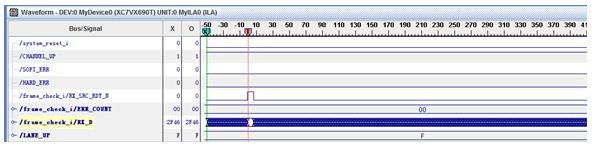
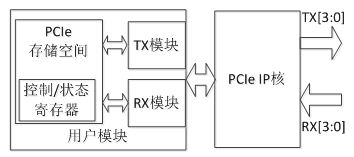
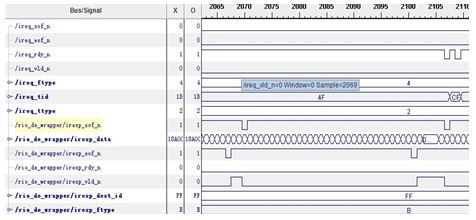
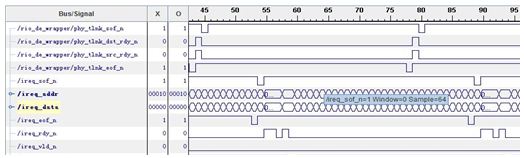
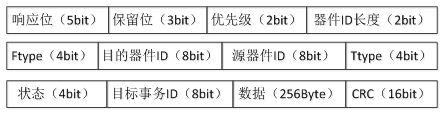
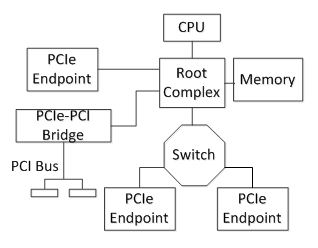
基于Virtex-6 FPGA的三种串行通信协议测试及对比
2015-4-26 17:33 上传
548ab3e9f2623-thumb.jpg (25.73 KB, 下载次数: 124)
548ab3ea176a2-thumb.jpg (15.2 KB, 下载次数: 138)
548ab3e9bf885-thumb.jpg (3.68 KB, 下载次数: 134)
548ab3e9bfd12-thumb.jpg (13.6 KB, 下载次数: 141)
548ab45fe21be-thumb.jpg (10.99 KB, 下载次数: 135)
548ab45faf2a2-thumb.jpg (14.84 KB, 下载次数: 118)
548ab45fe272e-thumb.jpg (27.21 KB, 下载次数: 135)
548ab45faf7a7-thumb.jpg (22.91 KB, 下载次数: 144)
548ab45fb7060-thumb.jpg (15.58 KB, 下载次数: 120)
548ab45fe21ce-thumb.jpg (12.19 KB, 下载次数: 137)
548ab4d3d58cb-thumb.jpg (10.7 KB, 下载次数: 130)
548ab4d39fb37-thumb.jpg (23.46 KB, 下载次数: 122)
548ab4d39bd69-thumb.jpg (15.97 KB, 下载次数: 127)
548ab4d3de1c1-thumb.jpg (8.41 KB, 下载次数: 125)
548ab4d3a006e-thumb.jpg (16.53 KB, 下载次数: 124)
548ab4d41e53a-thumb.jpg (15.47 KB, 下载次数: 121)
548ab4d42d01d-thumb.jpg (7.94 KB, 下载次数: 136)
548ab4d3b6aa4-thumb.jpg (8.15 KB, 下载次数: 136)
548ab56aa9f12-thumb.jpg (12.26 KB, 下载次数: 122)