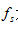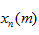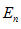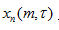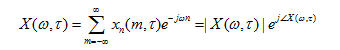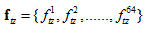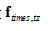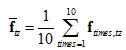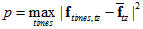DIY编程器网
标题: 基于FPGA的说话人识别系统,包含原理图、源代码 [打印本页]
作者: admin 时间: 2015-4-27 16:10
标题: 基于FPGA的说话人识别系统,包含原理图、源代码
项目实施背景及可行性分析:
随着网络信息化技术的迅猛发展,身份验证的数字化、隐性化、便捷化显得越来越重要。语言作为人类的自然属性之一,说话人语言具有各自的生物特征,这使得通过语音分析进行说话人识别(Speaker Recognition, RS)成为可能。人的语音可以非常自然的产生,训练和识别时并不需要特别的输入设备,诸如个人电脑普遍配置的麦克风和到处都有的电话都可以作为输入设备,因此采用说话人语音进行说话人识别和其他传统的生物识别技术相比,具有更为简便、准确、经济及可扩展性良好等众多优势。
说话人识别的研究始于20世纪60年代,如今在特征提取、模型匹配、环境适应性等方面的研究已臻于成熟,各种算法也趋于稳定,说话人识别技术也正逐步进入到实用化阶段。因此,我们根据已有的特征提取算法基于FPGA工具搭建说话人识别系统是可行的。
项目目前进度:
系统具体方案及模型已搭建成功,并采用最小距离算法对系统进行说话人确认和说话人辨认的matlab仿真。 仿真结果显示,识别成功。
项目实施方案:
1 项目基本框图:
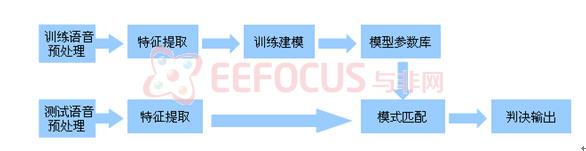
图1 说话人识别基本框图
图1是一个典型的说话人识别框图,包括训练和识别两个部分,训练又分为训练语音预处理、特征提取、训练建模、获取模型参数库四个过程,识别部分分为测试语音预处理、特征提取、模式匹配、判决输出四个过程。识别部分的模式匹配模块是将测试语音的特征矢量同模型库里的特征矢量进行距离匹配。
2 具体步骤
2.1 预处理
无论是训练语音信号还是测试语音信号在进行特征提取之前都要进行预处理。预处理包括预加重、分帧加窗、端点检测等。
(1)预加重:正常人的语音频率范围一般为40Hz~4000Hz,在求语音信号频谱时,频率越高相应的频谱成分越小,高频部分的频谱比低频部分的难求,预加重的目的是对语音信号的高频部分(大约800Hz以上)加以提升,是信号的频谱变得平坦,以便于频谱分析。预加重在语音信号数字化之后进行,用一阶数字滤波器来实现,公式为:
 (1)
(1)
其中,
为预加重系数,它的值接近1,本项目取0.9375。
(2)分帧加窗:语音信号在很短的一个时间内可以认为是平稳的,所以我们在对其处理时,先对语音信号分帧,对每帧信号处理就相当于对固定特性的持续语音进行处理。一帧语音信号时长约10~30ms,本系统采样频率
为22050Hz,所以,帧长N取256,帧移为128。.分帧后,对每帧信号采取加窗处理,为避免吉布斯效应,本系统采用长度为256的汉明窗,其表达式为:
(2)
其中
表示该窗的中心坐标。
(3)端点检测:端点检测的目的是从包含语音的一段信号中消除无声段的噪音和减少处理语音段的时间,确定出语音的起点以及终点。本系统通过短时能量的大小来区分清音段和浊音段。设第n帧语音信号的短时能量为
,其计算公式如下:
(3)
清音的能量较小,浊音的能量较大。
在进行说话人语音端点检测时,首先根据背景噪声确定一个短时能量的门限阈值,由于我们获取说话人语音信息时是在安静环境下进行的的,所以仅根据此门限来确定语音的起点和终点也是可行的。但为了避免突发性的瞬时噪声(其短时能量有时比较大)的干扰,我们在此基础上,进行了进一步的限定,即,一旦检测到某帧的短时能量超过了门限,我们再继续检测接下来的32(经验值)帧,如果在这32帧里有3/4(经验值)的帧其短时能量都超过了门限,我们才确定最初检测的帧为语音起点,否则继续下一帧的检测。实验仿真证明,这种方法相比于单纯通过门限值判断能更好地确定语音的起始点和终点。
2.2 特征提取、训练、识别
2.2.1 特征提取
语音信号的特征提取是说话人识别的关键问题。对一帧语音信号进行某种变换以后产生的相应矢量,如线性预测系数、LPC倒谱系数、线谱对参数、共振峰率、短时谱等。综合考虑性能和硬件实现复杂度,在本系统中我们选择语音信号的短时谱作为其特征参数。首先我们对分帧加窗后的语音信号进行短时傅里叶变换,得到每帧语音信号频谱的幅值分布,再根据这些频谱幅值分布提取每一帧的特征矢量。
设加窗后的第n帧语音信号记为
,其短时傅里叶变换表示为:
(4)
在本系统,我们用DFT来等价短时傅里叶变换。对所求得的帧信号的频谱幅值分布进行分析:每4个样本点求一次最大幅值,记录下对应最大幅值的那个样本点标号,这样长256的一帧信号可以得到64个这样的样本点。取这64个样本点组成的矢量向量为该帧的特征矢量。对输入语音的所有帧特征矢量求平均,得该输入语音的帧平均特征矢量,即该语音的特征矢量,记为
。
2.2.2 训练建模
在训练建模部分,我们建立识别模型,所谓识别模型,是指用什么模型来描述说话人的语音特征在特征空间的分布。对于说话人识别系统,特征参数被提取出来后,需要用识别模型为说话人建模,并对特征进行分类,以确定属于哪一个说话人。目前常用的识别模型有,最小距离模型,矢量量化模型,隐马尔可夫模型,高斯混合模型。综合考虑下,本系统采用最小距离模型对说话人语音进行训练。
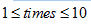
本系统实验时说话人训练次数取为10,首先对每次训练的输入语音求特征矢量
(
),再对10次训练产生的特征矢量求平均得到的平均特征矢量
,将此平均特征矢量作为说话人训练所得的模型特征矢量。
2.2.3 识别
说话人识别包括说话人辨别和说话人确认,说话人辨别是从多个说话人语音中辨认出某个人的那一段语音信息,而说话人确认是确定某段语音信息是不是某人所说。
我们用测试数据与训练数据的平均特征矢量之间的均方差作为一种距离度量。在说话人确认中,我们设定一个判决阈值
,如果测试者数据与训练数据的距离小于此阈值,我们就认为确认到了原说话人;在说话人辨认中,我们把与测试说话人距离最小的说话人作为目标说话人。
二、Matlab仿真结果
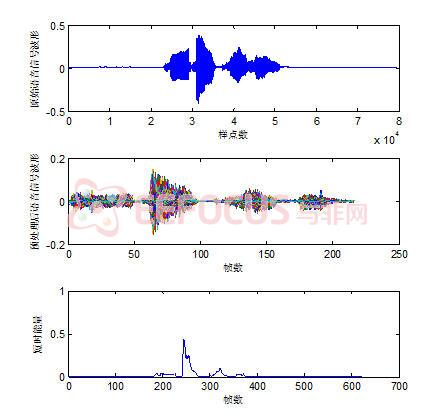
我们通过Windows自带的录音机得到声音数字信号,采样频率为22050Hz,单声道。说话人数为2,在训练阶段,每个说话人说10次‘芝麻开门’。
图2 说话人zx的测试语音‘zx316’的相关图
图3 语音信号‘zx316’第一帧的短时傅里叶频谱幅值分布
图4 语音信号‘bb13’第一帧的短时傅里叶频谱幅值分布
测试语音‘zx316’第一帧的特征向量:
1 8 12 16 19 23 27 31 33 38 43 46 50 53 57 64 65 72 73 80 81 88 91 96 97 103 106 111 113 117 122 125 132 136 140 141 147 152 153 160 161 167 169 176 177 183 186 190 193 198 202 208 209 215 220 221 227 231 235 239 241 245 249 256
测试语音‘bb13’第一帧的特征向量:
1 7 12 16 17 21 26 29 34 37 44 47 49 56 58 61 65 70 73 80 81 85 92 93 98 104 105 110 115 117 121 128 130 136 138 143 145 150 154 157 162 166 169 176 177 181 188 191 193 200 202 205 211 213 220 221 228 232 233 239 242 245 249 256
测试语音‘zx316’平均特征向量avtzv1:
2.8056 6.6157 10.5185 14.3009 18.6667 22.5972 26.1296 30.2361 34.6435 38.7407 42.1389 46.4444 50.4907 54.1296 58.6250 62.9583 66.1296 70.7546 74.2824 78.0000 82.1759 86.5324 90.3472 94.4583 98.4352 102.5926 106.3102 110.3009 114.4722 117.9537 122.1065 126.3889 130.5139 134.8333 138.8056 142.4167 146.6852 150.9120 154.2685 158.4537 162.5926 166.6204 170.3241 174.8426 178.8333 182.7963 186.4815 190.8796 194.2222 198.3935 203.2130 206.5648 210.2824 214.7963 218.1852 222.0787 226.6944 231.3287 234.9676 238.6435 242.8565 246.7037 250.3102 253.9491
测试语音‘bb013’平均特征向量avtz2:
2.6385 7.3991 10.3756 14.8357 18.7324 22.0423 26.1455 30.1643 34.5493 38.0423 42.7746 46.9014 49.6432 54.0751 58.5305 62.5493 66.7324 70.8216 75.1502 78.0376 81.9718 86.4695 90.6432 93.7700 99.2347 101.9390 106.6291 110.4883 113.9296 118.6854 122.0329 126.2817 130.5211 134.7418 138.3897 143.1972 146.7371 150.3615 155.1080 158.0376 163.1080 166.3991 170.8920 175.2441 179.2300 181.8075 185.8404 189.8826 194.5915 198.5587 202.5446 206.9061 210.4413 214.3568 218.5915 222.6197 226.2629 230.9108 235.0939 238.4648 241.8732 246.7606 249.9249 253.8216
十次训练后,说话人zx的模型特征向量zxtzv:
2.6470 6.3738 10.4790 14.1162 18.7036 22.6037 26.2209 29.9523 34.3714 38.8523 42.3689 46.4702 50.5910 54.0536 58.4656 62.8491 66.2164 70.5120 74.2916 78.2231 82.2290 86.6381 90.4263 94.4608 98.5462 102.5562 106.3308 110.3999 114.2824 118.1380 122.1408 126.2868 130.6763 134.8471 138.7515 142.6162 146.6641 150.7192 154.2886 158.3545 162.5407 166.5522 170.2916 174.8380 178.7560 182.8976 186.5329 190.8797 194.2625 198.4912 203.1178 206.6151 210.4543 214.7273 218.0488 222.2090 226.7668 230.8650 234.7660 238.3485 242.7473 246.7412 250.4028 253.8851
训练所得说话人zx的确认阈值为zxp:
0.0403
十次训练后,说话人bb的模型特征向量bbtzv:
2.5516 7.3047 10.2896 15.0233 18.7163 21.7753 25.8263 30.4965 34.4767 38.2047 42.6746 46.2591 49.9754 54.4766 58.5582 62.7232 66.4625 71.0343 74.8362 78.0749 82.2228 86.1855 90.2439 94.4314 98.5723 102.5504 106.2111 110.1579 114.2530 118.2325 122.2810 126.2972 130.5383 134.6598 138.7651 142.7511 146.8711 150.7495 154.4465 158.1874 162.6890 166.6006 170.9542 174.7016 179.1256 182.1497 186.1302 190.4031 194.2276 198.4698 202.4609 206.8553 210.8231 214.4258 218.5462 222.5539 226.4384 231.2354 235.0389 238.5223 241.7803 246.7281 249.9968 253.8746
训练所得说话人bb的确认阈值为bbp:
0.0940
说话人确认时:
- 计算测试语音语音1(zx036)的特征向量avtzv1与说话人zx的模型特征向量zxtzv的距离,为0.0196,小于说话人zx的确认阈值为zxp(0.0403),所以确认测试语音1为zx所说;计算测试语音2(bb13)的特征向量avtzv2与说话人zx的模型特征向量zxtzv的距离,为0.2310,大于说话人zx的确认阈值为zxp(0.0403),所以确认测试语音2不是zx所说。
- 计算测试语音语音1(zx036)的特征向量avtzv1与说话人bb的模型特征向量bbtzv的距离,为0.1292,大于说话人bb的确认阈值为bbp(0.0940),所以确认测试语音1不是bb所说;计算测试语音2(bb13)的特征向量avtzv2与说话人bb的模型特征向量bbtzv的距离,为0.0932,小于说话人bb的确认阈值为bbp(0.0940),所以确认测试语音2是bb所说。
说话人辨认:
- 计算测试语音语音1(zx036)的特征向量avtzv1与说话人zx的模型特征向量zxtzv的距离,为0.0196;计算测试语音语音1(zx036)的特征向量avtzv1与说话人bb的模型特征向量bbtzv的距离,为0.1292。所以,将测试语音1辨认为zx所说。
- 计算测试语音2(bb13)的特征向量avtzv2与说话人zx的模型特征向量zxtzv的距离,为0.2310;计算测试语音2(bb13)的特征向量avtzv2与说话人bb的模型特征向量bbtzv的距离,为0.0932。所以,将测试语音1辨认为bb所说。
三、 Matlab仿真程序:
1. 说话人确认主函数
%%####=============说话人确认主函数(最小距离)==============####%%
clc;clear;
%============1 流程说明========%
%将测试语音与训练所得模板逐个进行确认,先确定出要确认的说话人的模板的训练判决阈值,
%再求出每个测试语音的平均特征向量与此说话人模板特征向量的距离,如果距离小于阈值,
%则确认此测试语音为该说话人所说,否则不是。
%==========2 符号说明===========%
% N:说话人数;K: 特征矢量的长度;
% TZV:N*K阶的训练特征矢量矩阵,第nn行表示第nn个说话人的模型特征矢量;
% DTH: N长的训练判决门限向量,第nn个元素代表第nn个说话人的训练判决门限;
% S1: 说话人1的语音信号;S2:说话人2的语音信号;......;SN: 说话人N的语音信号
%=========3 主程序=======%
%===根据训练数据,求出各个说话人的训练特征矢量和训练判决门限===%
N=2;
TIMES=10;%训练次数为10
load A1 A1; %A1为说话人zx的十次训练语音组成的cell
load A2 A2; %A2为说话人bb的十次训练语音组成的cell
%.......%
[mtzh1,p1]=xunlian(A1,TIMES);%调用训练子函数,得说话人的模型特征矢量和模型判决门限
TZV(1,:)=mtzh1;
DTH(1)=p1;
[mtzh2,p2]=xunlian(A2,TIMES);
TZV(2,:)=mtzh2;
DTH(2)=p2;
%.......%
K=length(mtzh1);
%===说话人说话,轮流进行确认===%
%==确认说话人1==%
nn=1;
S1=wavread('f:\speakerzx3\zx316');%%说话人x说话后语音信息被存储,用函数读出该语音信号
decisionf(S1,TZV,DTH,nn,K) %确认说话人x是否为说话人1,是输出‘yes’,不是输出‘no’
S2=wavread('f:\speakerbb1\bb13');%%说话人y说话后语音信息被存储,用函数读出该语音信号
decisionf(S2,TZV,DTH,nn,K) %确认说话人y是否为说话人1,是输出‘yes’,不是输出‘no’
%......%
%==确认说话人2==%
nn=2;
S1=wavread('f:\speakerzx3\zx316');%%说话人x说话后语音信息被存储,用函数读出该语音信号
decisionf(S1,TZV,DTH,nn,K) %确认说话人x是否为说话人2,是输出‘yes’,不是输出‘no’
S2=wavread('f:\speakerbb1\bb13');%%说话人2说话后语音信息被存储,用函数读出该语音信号
decisionf(S2,TZV,DTH,nn,K) %确认说话人y是否为说话人2,是输出‘yes’,不是输出‘no’
%......%
%=====......=====%
2.说话人辨认主函数
%%####=============说话人辨别主函数(最小距离)==============####%%
clc;clear;
%============1 流程说明========%
%对要进行辨认的测试说话人提取平均特征向量,和训练库中的每个模板特征矢量进行距离比较,我们把与测试说话人具有最小距离的说话人作为目标说话人。
%==========2 符号说明===========%
% N:说话人数;K: 特征矢量的长度;
% TZV:N*K阶的训练特征矢量矩阵,第nn行表示第nn个说话人的模型特征矢量;
% DTH: N长的训练判决门限向量,第nn个元素代表第nn个说话人的训练判决门限;
% S1: 说话人1的语音信号;S2:说话人2的语音信号;......;SN: 说话人N的语音信号
%=========3 主程序=======%
%===根据训练数据,求出各个说话人的训练特征矢量和训练判决门限===%
N=2;
load A1 A1;
load A2 A2;
TIMES=10;%训练次数为10
[mtzh1,p1]=xunlian(A1,TIMES);%调用训练函数,得说话人的模型特征矢量和模型判决门限
TZV(1,:)=mtzh1;
[mtzh2,p2]=xunlian(A2,TIMES);
TZV(2,:)=mtzh2;
K=length(mtzh1);
%===说话人说话,进行辨认===%
%==辨认说话人1==%
S1=wavread('f:\speakerzx3\zx316');%%说话人1说话后语音信息被存储,用函数读出该语音信号
identify(S1,TZV,N,K)
%==辨认说话人2==%
S2=wavread('f:\speakerbb1\bb13');%%说话人2说话后语音信息被存储,用函数读出该语音信号
identify(S2,TZV,N,K)
3 .子函数1——输入训练语音数据,输出训练所得模式训练特征矢量及判决阈值
function [mtzh,p]=xunlian(A,TIMES)
%===输入为训练次数TIMES和每次的训练语音信号的合集A;输出为训练所得模型特征矢量及模型判决门限===%
for tt=1:TIMES %10指每个说话人的训练次数
avertzvector(tt,:)=tzhvf(A{tt});
end
mtzh=sum(avertzvector)/TIMES;
%%==========确定判决门限dehood1=======%%
for ts=1:TIMES
chavec=mtzh-avertzvector(ts,:);
wucha(ts)=chavec*chavec'/length(mtzh);
end
p=max(wucha);
4. 子函数2——特征特取子函数
输入语音信号,输出特征矢量
%===提取输入语音信息的特征矢量===%
function avertzvector=tzhvf(x1)
lent1=length(x1);
%%=======预加重更新x1=======%%
u=0.9375;
for num=2:lent1
x1(num-1)=x1(num)-u*x1(num-1);
end
%%=======将语音信号进行分帧得y1,加窗得winy1=======%%
framelen=256;%帧长
shift=128;%帧移
numframe=ceil(lent1/shift)-1;%%帧数
for numw=1:framelen
hw(numw)=0.54-0.46*cos(2*pi*(numw-1)/(framelen-1));%%汉明窗
end
for num1=1:numframe
a=(num1-1)*framelen/2+1;
b=(num1-1)*framelen/2+framelen;
if b<=lent1
y1(num1,:)=x1(a:b);
else
y1(num1,:)=[(x1(a:lent1))',zeros(1,b-lent1)];
end
winy1(num1,:)=y1(num1,:).*hw;%%分帧加窗后的数据
end
%%=========求信号的短时能量e1==========%%
e1=sum(winy1.^2,2);%%sum(x,2)表示将矩阵x横向相加,得到每行的和,为一个列向量
%%========利用短时能量进行端点检测得到起始帧号startnum和结束帧号endnum==========%%
menxian=9e-04;
duliang=32;
for startnum=1:length(e1)
if e1(startnum)>menxian
indc=find(e1(startnum+1:startnum+duliang)>menxian);
if length(indc)/duliang>=3/4
break;
end
end
end
for endnum=length(e1):-1:1
if e1(endnum)>menxian
indc=find(e1(endnum-duliang:endnum-1)>menxian);
if length(indc)/duliang>=3/4
break;
end
end
end
data1=winy1(startnum:endnum,:);%%data为去除无声段的语音数据(分帧加窗后的)
%%===========短时傅里叶变换=============%%
newnumframe=endnum-startnum+1;
for num2=1:newnumframe
STFTdata1(num2,:)=abs(fft(data1(num2,:),framelen));
%SFTwindata1(num2,:)=abs(windata1(num2,:)*exp(-1j*2*pi/framelen*(0:255)'*(0:255)));
end
%%=======对每帧求特征向量=========%%
jiange=4;%每四个点找一次频谱幅度最大值
for k=1:newnumframe
for kk=0:framelen/jiange-1
aa=jiange*kk+1;
bb=jiange*kk+jiange;
[maximum,ind]=max(STFTdata1(k,aa:bb));
tzvector(k,kk+1)=ind+jiange*kk;%%特征向量
end
end
avertzvector=sum(tzvector)/newnumframe;%语音帧平均特征矢量
5. 子函数3——说话人确认子函数
输入测试语音,输出确认结果
function decisionf(S,TZV,DTH,nn,K)
%判决子函数,输入说话人语音S,模板特征向量矩阵TZV,模板判决门限DTH,说话人数N,特征向量长度K;输出判决结果
avtzvS=tzhvf(S);%%调用子函数tzhvf提取该语音信息的特征矢量
if (TZV(nn,:)-avtzvS)*(TZV(nn,:)-avtzvS)'/K<=DTH(nn)
disp('Yes.');
else
disp('No.');
end
6.子函数4——说话人辨认子函数
输入测试语音,输出辨认结果
function identify(S,TZV,N,K)
%判决子函数,输入说话人语音S,模板特征向量矩阵TZV,模板判决门限DTH,说话人数N,特征向量长度K;输出判决结果
avtzvS=tzhvf(S);%%调用子函数tzhvf提取该语音信息的特征矢量
for nn=1:N
distance(nn)=(TZV(nn,:)-avtzvS)*(TZV(nn,:)-avtzvS)'/K;
end
[~,snum]=min(distance);
fprintf('The speaker is %d\n',snum);
| 欢迎光临 DIY编程器网 (http://diybcq.com/) |
Powered by Discuz! X3.2 |