50bb45032dcbc-thumb.png (40.95 KB, 下载次数: 119)
下载附件 保存到相册
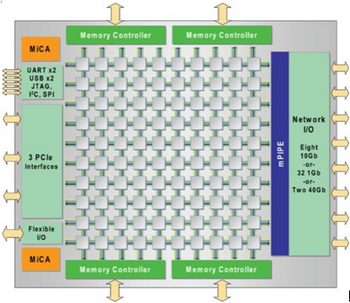
多核处理器可替代FPGA
2015-4-27 17:36 上传
50bb45033538a-thumb.png (22.93 KB, 下载次数: 123)
50bb450335900-thumb.png (29.76 KB, 下载次数: 125)
50bb450336202-thumb.png (24.59 KB, 下载次数: 118)