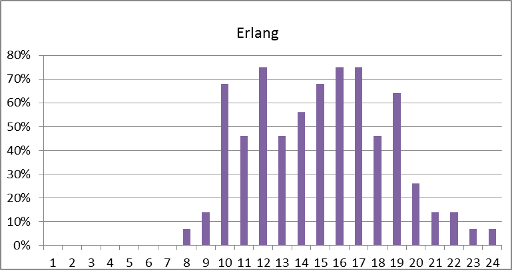
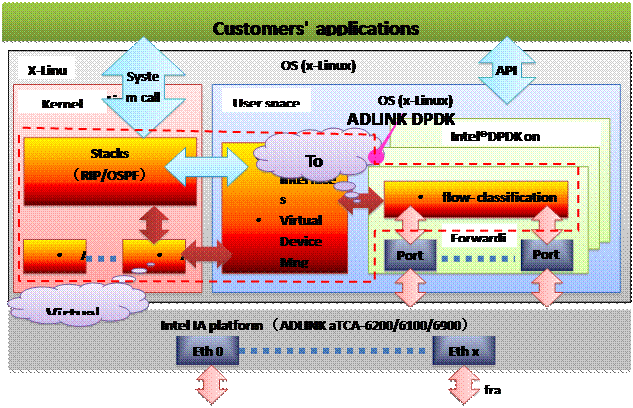
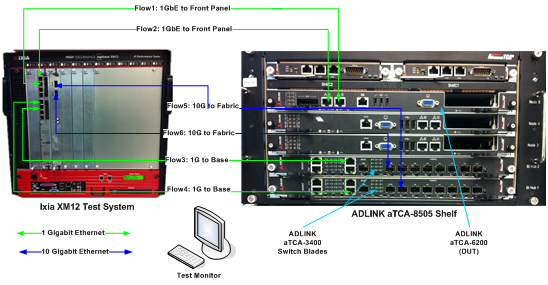
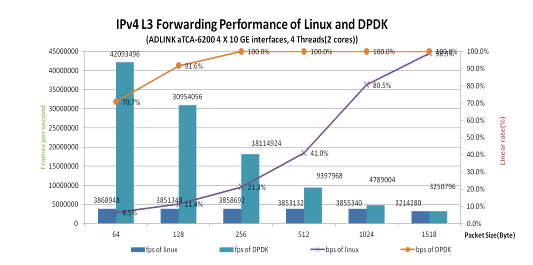
关于凌华
凌华科技致力于量测、自动化及计算机通讯科技之改进及创新,提供解决方案给全球网络电信、智能交通及电子制造客户。凭着对专业技术的执着与实践客户承诺的自我要求,领先业界推出多项创新性产品,获ISO-9001、ISO-14001、ISO-13485、台湾精品、TL9000等多项认证。凌华科技为Intel?智能系统联盟(Intel? Intelligent Systems Alliance)会员,PICMG协会和PC/104协会可参与制定规格的会员,PXI Systems Alliance协会董事会及最高等级会员,以及AXIe联盟战略会员,VMEbus国际贸易协会(VITA)成员。目前在美国、新加坡、中国、日本、德国设有子公司,在印度、韩国、法国设有办事处,为当地客户提供快捷服务和实时支持。网址:http://www.adlinktech.com/cn。