52bd3a54d31f4-thumb.jpg (16.18 KB, 下载次数: 596)
下载附件 保存到相册
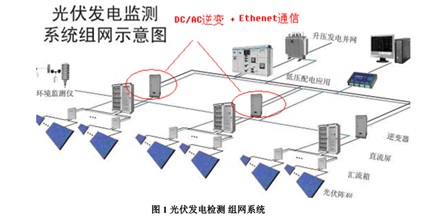
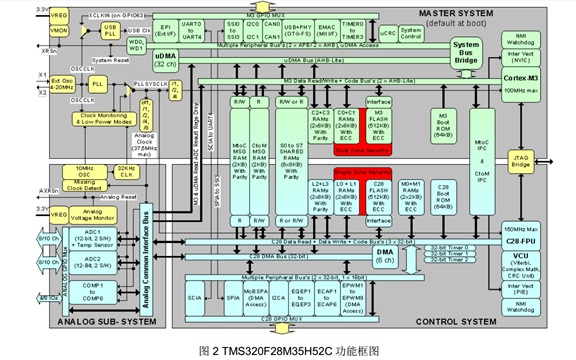
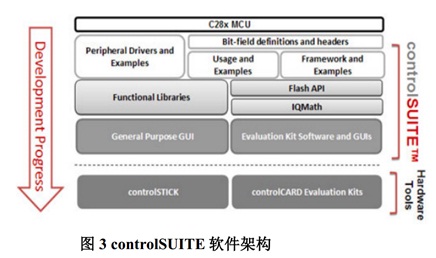
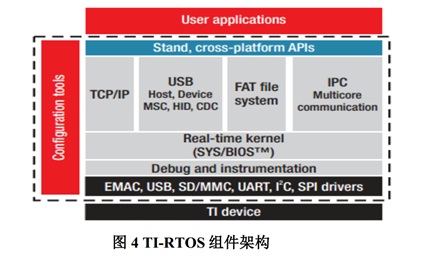
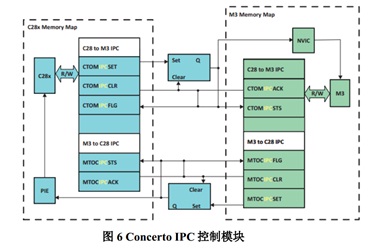
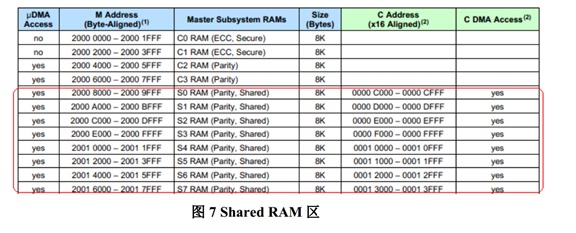
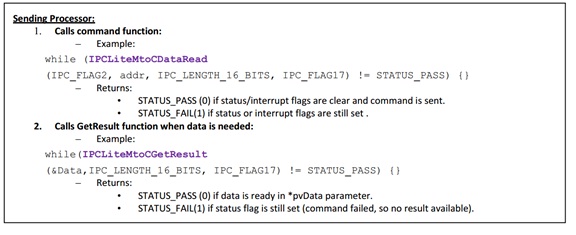
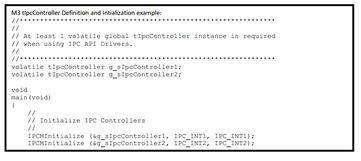
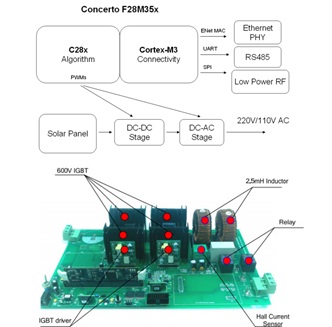
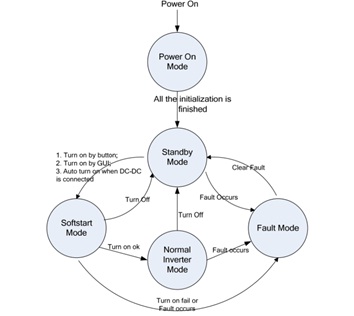
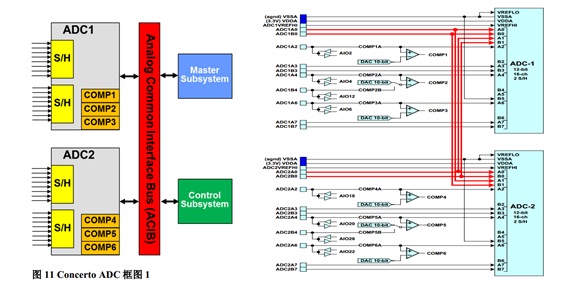
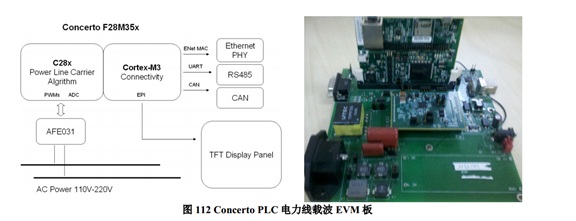
基于 C2000 Concerto 系列采用非对称双核 MCU 提高系统性能
2015-4-27 23:54 上传
52bd3a5514055-thumb.jpg (36 KB, 下载次数: 606)
52bd3a5501cac-thumb.jpg (19.28 KB, 下载次数: 616)
52bd3a557436f-thumb.jpg (20.38 KB, 下载次数: 580)
52bd3a5548db1-thumb.jpg (7.39 KB, 下载次数: 597)
52bd3a554da54-thumb.jpg (17.38 KB, 下载次数: 623)
52bd3a557c2b8-thumb.jpg (24.97 KB, 下载次数: 623)
52bd3a55d25eb-thumb.jpg (15.92 KB, 下载次数: 614)
52bd3a55a872c-thumb.jpg (19.41 KB, 下载次数: 620)
52bd3a55d9ff2-thumb.jpg (16.14 KB, 下载次数: 615)
52bd3a561c298-thumb.jpg (9.6 KB, 下载次数: 612)
52bd3a568488f-thumb.jpg (11.63 KB, 下载次数: 592)
52bd3a5658593-thumb.jpg (17.62 KB, 下载次数: 617)
52bd3a5696378-thumb.jpg (15.9 KB, 下载次数: 620)
52bd3a56777ae-thumb.jpg (11.32 KB, 下载次数: 631)
52bd3a570378b-thumb.jpg (23.99 KB, 下载次数: 634)
52bd3a56e4580-thumb.jpg (13.6 KB, 下载次数: 615)