=Ci0*[f(i,0)-f(i,7)]+Ci0*[f(i,1)-f(i,6)]+Ci0*[f(i,2)-f(i,5)]
+Ci0*[f(i,3)-f(i,4)]
因此向量在做内积运算的过程中,可以先对输入向量轮流进行加法和减法的操作,之后再和相应的系数做内积运算,这样可以是乘法器的数量减少一半,节约了系统资源,付出的代价是增加了一轮加法处理的时间,在考虑到FPGA资源有限的情况下使用这种方法来优化设计。在做完一轮DCT变换之后,需要对中间矩阵进行转置处理,然后进行第二轮的DCT变换。
2.1.2 FPGA硬件设计结构:
对于具有256种像素值补码表示范围为-128—+127,需要8位二进制数据来表示;DCT变换后系数的动态范围为-1024—+1016,使用12位二进制数表示输出,DCT变换的过程中,需要处理余弦函数,小数和整数相乘十分困难,因此在考虑到精度的情况下,先把8个固定系数乘以一个整数,将小数转换成整数,系数都乘以211,对转换后的整数,先用这个整数和乘法器相乘,得到中间结果,再对中间结果除以211 ,即结果向右移动11位,这个过程中要对右起的第十一位数进行1进位,0丢弃的方法取舍。8个系数处理过以后得到如下结果:
C0= 0.35355=10b’ 1011010100 C1= 0.4904 =10b’ 1111101100
C2= 0.46195=10b’ 1110110010 C3= 0.41575=10b’ 1101010011
C4= 0.35355=10b’ 1011010100 C5= 0.2778 =10b’ 1000111001
C6= 0.19135=10b’ 0110001000 C7= 0.09755=10b’ 0011001000
图3
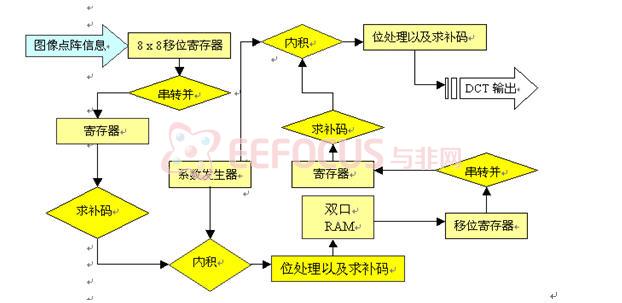
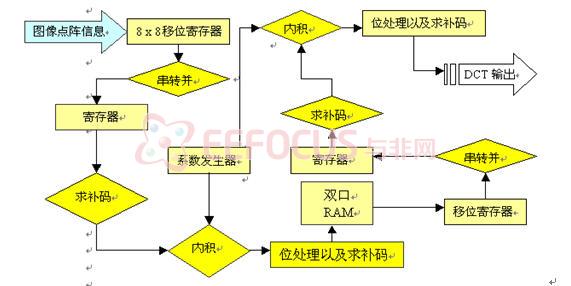
整个设计采用并行流水线的工作方式,对于8位的图像数据,输入输出均采用补码表示,硬件结构流程图见图3:
下面对一维DCT变换进行分析:
一维DCT变换按照行的顺序每个时钟上升沿读入一个像素值即8位二进制数据,数据先要送到一个8x8的移位寄存器,并设置一个模8计数器,当每计数器寄到8时,移位寄存器的数据已经填满,此时一行的数据全部读入,在下一个时钟上升沿数据一并送到下一组寄存器中,之后对数据进行求绝对值运算和符号保存,然后这个向量与系数发生器产生的系数做内积运算,内积运算过程中,按照前述的提公因式方法,先进行一轮加法,接着再做乘加运算,最后对结果做补码运算得到中间结果,并把这个数据存入中间RAM之中。
对于中间矩阵存储部件,第一轮计算结果不断送入其中,当数据读满之后,第二轮DCT变换开始工作,并按照中间矩阵的列顺序读入数据,送到第二轮的DCT部件做运算。
中间RAM可以看成是8x8的存储阵列。当写入数据时,按照0,1,2,3,4…,63的地址顺序进行;当读出数据时按照0,8,16,……,56; 1, 9, 17,……,57,……,7, 15, 23,……,63进行。
IDCT的硬件结构和DCT的硬件结构相同,只是系数矩阵要进行转置,这样就无法进行提公因式操作,因此IDCT比DCT多用一倍的乘法器。
2.3系统实现方案:
2.3.1系统总体方案:
图4
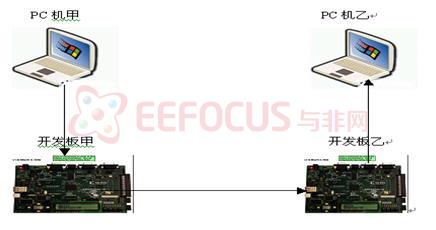
本系统如图5所示,由于单个开发板硬件资源有限,所以采用两个板子来完成本系统,第一块板子完成第一部分处理之后,中间数据送到第二块板子进行处理,最后处理完的数据送回PC机。
系统流程:
设宿主图像为H,嵌入的图像为E,嵌入图像后的宿主图像为H’,则:
(1).嵌入水印的过程:
水印预处理过程,使用密钥在PC机甲上完成对嵌入图像E的变换,使之成为一幅没有视觉意义的图片E’;
把宿主图片H和图片E’通过串口送到板子,并存入板子甲的DDR SDRAM中,然后板子甲对送入的信息进行初步处理,处理之后的中间结果通过串口送到开发板乙的DDR SDRAM中,进行第二步的处理。
经过开发板处理处理之后,得到嵌入了E’的图片H’,再通过串口把这个图片送到PC机乙。
(2).提取验证水印的过程:
提取水印的过程中,只需对嵌入了水印的图片做DCT变换,只需开发板甲,因此流程如下,PC机乙把嵌入了水印的图片H送入到开发板甲的DDR SDRAM中暂存。开发板甲对收到的图片信息的处理, 提取水印,完成之后把提出出的水印回送到PC机甲,PC机甲利用密钥恢复出原来嵌入的图片,并进行验证。
2.3.2 硬件及软件架构
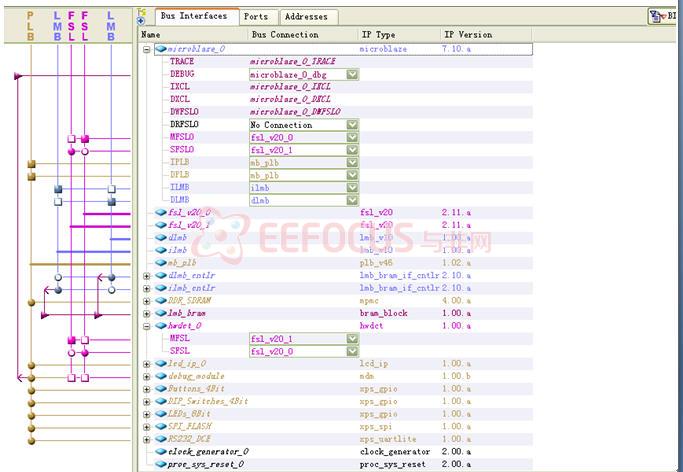
本系统依靠EDK开发环境,应用microblaze软核,加上一些用户定义IP核,实现了对bmp格式位图进行数字水印处理。水印算法要在频域中做,故需要进行变换域处理[2],我们选择了在图像处理领域广泛应用的二维离散余弦变换。由于像二维离散余弦变换这样复杂的信号处理过程非常复杂,直接在microblaze中用软件处理是非常耗时的,我们采用microblaze提供的FSL接口用硬件实现DCT及IDCT,进行硬件加速,试验表明,硬件实现速度远远超过了软件,后面的试验数据表明,一幅256*256的灰度图像若用软件实现至少需要40多个小时,而采用硬件加速后只需短短几分钟。
(1)系统控制框架:由于DCT和IDCT模块需要占用很多的乘法器(DCT8个,IDCT16个),而一个系统只提供20个,我们只好用硬件描述语言自己写了乘法器模块来代替不够的系统提供的乘法器,但这样系统LUT资源又不够了,经过优化,我们还是没能解决这个问题,最终,最优化的资源利用如表3所示:
Logic
Utilization
| Total Number Slice Registers: 6,364 out of 9,312 68%
|
Number used as Flip Flops: 6,358
|
Number used as Latches: 6
|
Number of 4 input LUTs: 9,371 out of 9,312 100% (OVERMAPPED)
|
Logic
Distribution
| Number of Slices containing only related logic: 10,066 out of 10,066 100%
|
Number of Slices containing unrelated logic: 0 out of 10,066 0%
|
Total Number of 4 input LUTs: 9,696 out of 9,312 104% (OVERMAPPED)
|
Number used as logic: 8,226
|
Number used as a route-thru: 325
|
Number used for Dual Port RAMs: 1,008
|
Number used as Shift registers: 137
|
Number of bonded IOBs: 62 out of 232 26%
|
IOB Flip Flops: 34
|
IOB Master Pads: 1
|
IOB Slave Pads: 1
|
Number of ODDR2s used: 22
|
Number of DDR_ALIGNMENT = NONE 22
|
Number of DDR_ALIGNMENT = NONE 22
|
Number of DDR_ALIGNMENT = C0 0
|
Number of DDR_ALIGNMENT = C1 0
|
Number of RAMB16s: 7 out of 20 35%
|
Number of BUFGMUXs: 4 out of 24 16%
|
Number of DCMs: 2 out of 4 50%
|
Number of MULT18X18SIOs: 20 out of 20 100%
|
表3
最后,我们放弃了在一块板子上同时做dct和idct的努力,决定用两块板子分别实现两种变化,且板间用串口进行通信,这样做增加了数据传输的冗余时间,但和软件实现相比还是有很的优势的。
(2)软件流程:
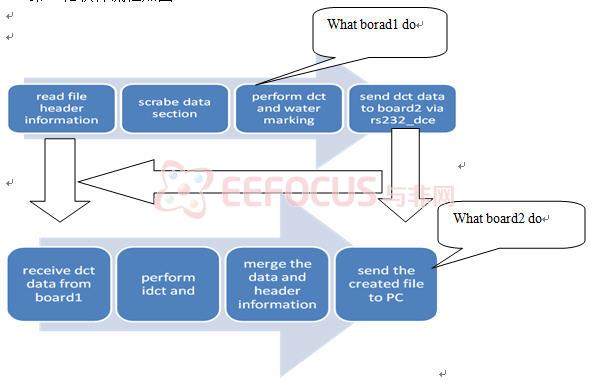
第一轮软件流程如图5:
图5
其中用到的led和dip用于控制,在board1上,流程细分为5步:
Stage1:read file
Stage2:print file information
Stage3:perform dct
Stage4:embed warter mark
Stage5:send data
每做一步亮一盏灯,当五盏灯全亮时,board也就完成了他的任务,同时,在流程中,超级终端和board中的lcd会一直显示板子的工作状态。Dip的作用是保持两块板子之间通讯的同步,board1在工作过程中会提示把com连至board2的DTE,然后,推动board1的dip1,board1就开始向board2发送数据。
在board2上主要是做idct变换,以及把做两次变换后的数据和文件头整合在一起,最后把嵌入了水印的图像数据发送给pc机。
第二轮软件流程:
第二轮比较简单,主要是从pc机中读取嵌入了水印的图像,并在board1上做dct,在频域中提取嵌入的水印。最后发送给pc机进行验证。
(3)配置方案:
board1用rs232_dce作为标准输入输出,lmb_bram作为初始引导内存,用户程序放在spi_flash里面,引导程序和硬件数据的比特流整合成初始配置mcs文件下载到spi_flash里。启动时用spi方式配置,引导程序从spi?_flash里由预先定好的位置拷贝用户程序到ddr_sdram里,并转跳至ddr_sdram的用户程序区,开始工作。
Board2配置方案基本和board1一样。
(4)处理器与外围接口:
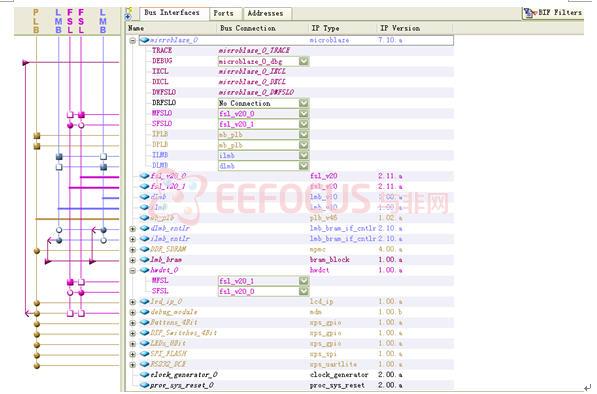
处理器配置为支持基本浮点,16kb的bram,无缓存,每块板子一对fsl接口,用于硬件加速。Fsl的fifo设为64,刚好符合dct算法中8*8数据块的要求。处理时只需调用一次函数刚和做一次8*8的dct操作。Flash选用16Mbit ST Micro SPI serial flash,这是由于系统的XCF04S serial platform flash太小,不足以容下用户程序。Fsl总线接口借用系统的example的状态链,加上另外一些必要的状态,在1500个时钟周期内完成一次dct变化,结构图如图6:
图6
(5)外围通讯方案:
由于一块板子不能同时放下dct和idct,故两板之间必须提供通讯接口。Board1和board2都提供rs232_dce作为标准输入输出,board2附加提供rs232_dte作为与board1上rs232_dce的通讯接口。二者的同步通过标准输入输出的提示,由dip_button的配置实现。板子和pc机的通讯由现成的串口精灵提供。
3. 功能与指标
3.1 功能
整个系统实现的功能分为两步:首先,将一幅灰度图片嵌入到载体图片中去,得到嵌入水印的图片。然后,从含水印的图片中提取出嵌入的水印图片。
3.2 指标
3.2.1 不可感知性评价
数字水印的不可感知性评价又称透明性评价[3]。数字水印的嵌入信息量与透明性之间存在着矛盾,随着嵌入水印信息量的增加,水印载体的感官质量必然下降,因为从一定意义上讲,水印信息对于原始信息来说,本身就属于噪声。在实际中,这两个指标往往很难同时实现,应用中往往只偏重其中的一个方面。如果是为了隐蔽通信,数据量是最重要的,而如果为了保证数据安全,情况则相反,鲁棒性是最重要的。本设计中,对嵌入的信息量不强调,故重点放在图像质量上。
嵌入水印后载体图像的客观评估指标主要是峰值信噪比,一般来说,图像处理前后的峰值信噪比越小,图像的质量降低就越多。但这种评价并没有从根本上反映出图像处理前后在视觉上的变化情况。人眼对图像的感受是一个总体的感受。从根本上说,图像最终是由人来感观的,因此我们采用主观评估来衡量水印的透明性。我们的测试方法是评价对图像质量损害的可感知程度,根据ITU-R BT.500建议,采用5个等级:优秀(5分,降质不可察觉)、良好(4分,降质可察觉,不让人厌烦)、一般(3分,降质轻微,让人厌烦)、差(2分,降质让人厌烦)、极差(1分,降质非常让人厌烦)来定义图像受损质量。因为每个人的感受是不一样的,故检测时尽可能多的综合多人的评价,得到平均等级。
3.2.2 鲁棒性评价
目前没有任何一种方法来对某个数字水印系统的鲁棒性进行数学证明,常用的思路是:能够经受住现有鲁棒性攻击的数字水印就是鲁棒性好的水印。因此鲁棒性评价是建立在相应攻击的基础之上的。设计中我们主要进行了一些几何攻击和简单攻击:对嵌入水印的图像进行剪切、旋转、压缩、添加随机的噪声,然后提取出水印图片,与原始水印图像进行比对,判断水印的失真、变形情况。给出3个等级:好(失真较小,能反映原始水印的信息),中(失真较大,但能基本反映原始水印的信息),差(失真大,不能反映原始水印的信息),来评价失真情况。
4. 系统结构特点
本设计的结构特点是:
(1) 采用了基于DCT域的算法,在中频系数中嵌入水印,这样既保证水印的不可见性,又保证水印的鲁棒性,达到了一个平衡。
(2) DCT模块和IDCT模块都采用流水工作方式,由两片双口RAM,实现了数据的流水输入输出,在计算第N组数据的同时,第N-1组的数据的结果正在串行输入。从而节省了处理数据的时间,提高了工作效率。
(3) 设计中将两个模块作为用户IP核连接到FSL总路线上,由此整合到基于MicroBlaze的嵌入式软核处理器系统中。FSL是MicroBlaze软核特有的一个基于FIFO的单向链路,可以实现用户自定义IP核与MicroBlaze内部通用寄存器的直接相连。并且FSL总线则适用于对时间要求高的用户自定义IP核,以实现硬件加速。
(4) 采用了块浮点算法,不止可以解决精度问题,且硬件实现的结构和控制都很简单。
(5) 系统设计中对载体图片的大小没有特殊的要求,可以是灰度图片,也可以是真彩色图片,且格式上也可以不限于bmp格式,可以适当的进行扩展。
5.系统自测试方案
5.1 测试环境
FPGA中的EDK、SDK及 ISE 开发环境,windows XP操作系统,matlab软件环境
5.2 测试设备
FPGA Spartan-3E初级板两块.
笔记本电脑一台 配置为CPU::Genuine Inter(R) T2050 主频1.60GHZ,内存:1.5G 主频798MHZ.
USB-Platform数据线两根,PC3下载线一根.
5.3 测试过程及结果分析
5.3.1 DCT模块的测试
为了保证测试结果的可靠性,我们选取了二组具有代表性的数据:
第一组:1~64的自然数序列
第二组:完全的随机序列,如表4:
95
| -56
| -111
| 29
| -22
| 115
| 116
| -88
|
63
| 102
| -56
| 29
| -126
| -125
| 95
| -56
|
37
| 62
| -86
| 101
| -12
| -86
| 15
| -110
|
73
| 93
| -110
| 7
| 60
| -8
| 103
| -66
|
-72
| 5
| -48
| 91
| 15
| -112
| 29
| -18
|
-14
| 37
| -84
| -8
| 103
| -54
| 25
| 5
|
-62
| 95
| -60
| -96
| 63
| -22
| 98
| 63
|
117
| -88
| 3
| 87
| -56
| 93
| -105
| -126
|
表4
测试步骤:首先,在matlab上对数据进行计算得到准确的结果;其次,在Xilinx上进行FPGA仿真得到仿真结果;最后,硬件实现并将数据输出到PC机上,得到最终数据。
(1) 第一组数据
matlab结果,如表5:
260.0000
| -18.2216
| 0.0000
| -1.9048
| 0
| -0.5682
| 0.0000
| -0.1434
|
-145.7731
| 0
| 0
| 0
| 0
| 0
| 0
| 0
|
0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
|
-15.2385
| 0
| 0
| 0
| 0
| 0
| 0
| 0
|
0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
|
-4.5459
| 0
| 0
| 0
| 0
| 0
| 0
| 0
|
0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
|
-1.1473
| 0
| 0
| 0
| 0
| 0
| 0
| 0
|
表5
FPGA仿真结果如表6:
260
| -17
| 0
| -3
| 0
| 0
| 0
| 0
|
-145
| 0
| 0
| 0
| 0
| 0
| 0
| 0
|
0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
|
-15
| 0
| 0
| 0
| 0
| 0
| 0
| 0
|
0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
|
-5
| 0
| 0
| 0
| 0
| 0
| 0
| 0
|
0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
|
-2
| 0
| 0
| 0
| 0
| 0
| 0
| 0
|
表6
硬件实现结果如表7:
260
| -17
| 0
| -3
| 0
| 0
| 0
| 0
|
-145
| 0
| 0
| 0
| 0
| 0
| 0
| 0
|
0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
|
-15
| 0
| 0
| 0
| 0
| 0
| 0
| 0
|
0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
|
-5
| 0
| 0
| 0
| 0
| 0
| 0
| 0
|
0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
|
-2
| 0
| 0
| 0
| 0
| 0
| 0
| 0
|
表7
(2 ) 第二组数据
matlab结果如表8:
5.3750
| 9.6394
| 51.7052
| 38.4342
| 47.6250
| 0.741
| -277.2674
| 8.5313
|
-4.9908
| 113.179
| 29.9029
| 177.4131
| -58.4884
| 270.5674
| -67.2188
| -132.3190
|
3.5962
| -51.6039
| 53.3457
| -26.3922
| -27.2503
| -39.9457
| 140.2216
| 28.9813
|
18.151
| -105.4604
| -5.125
| 95.4917
| -15.1833
| 48.4768
| -1.8645
| -12.0554
|
7.8750
| -32.5188
| -73.2229
| 22.7436
| 28.1250
| 9.7490
| 92.7028
| 15.2282
|
85.5709
| -81.2816
| 29.2330
| 184.0511
| -46.2973
| -21.3934
| -14.3454
| -5.8041
|
-23.0021
| 32.0408
| -113.5284
| 43.7507
| 78.2605
| -4.7500
| 61.6543
| -1.6563
|
-33.1766
| -29.2447
| -53.8318
| -62.7238
| 10.3477
| 31.7502
| 5.5105
| -33.7774
|
表8
FPGA仿真结果如表9:
6
| 10
| 52
| 38
| 48
| 1
| -277
| 9
|
-5
| 113
| 30
| 177
| -59
| 271
| -68
| -132
|
4
| -52
| 53
| -26
| -27
| -41
| 140
| 29
|
19
| -106
| -5
| -95
| -15
| 48
| -2
| -12
|
8
| -33
| -73
| 22
| 28
| 10
| 93
| 15
|
86
| -82
| 29
| 184
| -46
| -21
| -15
| -5
|
-23
| 32
| -113
| 43
| 77
| -5
| 62
| -2
|
-34
| -29
| -53
| -62
| 10
| 32
| 62
| -33
|
表9
硬件实现结果如表10:
6
| 10
| 52
| 38
| 48
| 1
| -277
| 9
|
-5
| 113
| 30
| 177
| -59
| 271
| -68
| -132
|
4
| -52
| 53
| -26
| -27
| -41
| 140
| 29
|
19
| -106
| -5
| -95
| -15
| 48
| -2
| -12
|
8
| -33
| -73
| 22
| 28
| 10
| 93
| 15
|
86
| -82
| 29
| 184
| -46
| -21
| -15
| -5
|
-23
| 32
| -113
| 43
| 77
| -5
| 62
| -2
|
-34
| -29
| -53
| -62
| 10
| 32
| 62
| -33
|
表10
(3 ) 测试数据分析
测试中,时钟周期为20ns,仿真时间为5000ns。
从两组数据可以看出,仿真结果与硬件实现的结果是一致的,与实际结果数据相差在正负1.5之间,这是由cos( )的计算精度造成的,但相差不大,符合设计中的数据要求。
5.3.2 IDCT模块的测试
为了使数据更有说服力,我们对上面两组变换后的数据进行反变换
(1) 第一组:
FPGA仿真结果为:
1 2 3 4 4 5 6 7 9 10 11 12 13 13 15 16 17 18 19 20 20 21 22 23 25 26 27 28 28 29 31 31 33 34 35 36 36 37 38 39 41 42 43 44 44 45 46 47 48 49 51 52 52 53 54 55 57 58 59 60 60 61 62 63
硬件实现结果为:
1 2 3 4 4 5 6 7 9 10 11 12 13 13 15 16 17 18 19 20 20 21 22 23 25 26 27 28 28 29 31 31 33 34 35 36 36 37 38 39 41 42 43 44 44 45 46 47 48 49 51 52 52 53 54 55 57 58 59 60 60 61 62 63
(2) 第二组
FPGA仿真结果如表11:
94
| -56
| -111
| 29
| -22
| 115
| 116
| -88
|
63
| 102
| -56
| 29
| -126
| -126
| 95
| -56
|
37
| 62
| -86
| 101
| -12
| -86
| 15
| -110
|
73
| 93
| -110
| 7
| 60
| -8
| 103
| -66
|
-72
| 5
| -48
| 91
| 15
| -112
| 28
| -18
|
-14
| 37
| -84
| -8
| 103
| -54
| 25
| 5
|
-62
| 95
| -60
| -96
| 63
| -22
| 98
| 63
|
117
| -88
| 3
| 87
| -56
| 93
| -105
| -126
|
表11
硬件实现结果如表12:
94
| -56
| -111
| 29
| -22
| 115
| 116
| -88
|
63
| 102
| -56
| 29
| -126
| -126
| 95
| -56
|
37
| 62
| -86
| 101
| -12
| -86
| 15
| -110
|
73
| 93
| -110
| 7
| 60
| -8
| 103
| -66
|
-72
| 5
| -48
| 91
| 15
| -112
| 28
| -18
|
-14
| 37
| -84
| -8
| 103
| -54
| 25
| 5
|
-62
| 95
| -60
| -96
| 63
| -22
| 98
| 63
|
表12
从两组数据看出,仿真结果与硬件结果是一致的。结果数据与原始输入数据相差在正负1之间,且输入数据越随机,结果越准确。这说明我们的模块设计是可靠的,准确的。
5.3.3 系统功能测试
测试中选取载体水印图像为:lena.bmp
图7
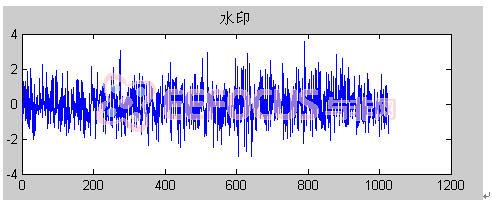
选取嵌入的水印为一串随机序列,其坐标图为:
图8
经过水印嵌入过程,得到嵌入水印后的图片为:
图9
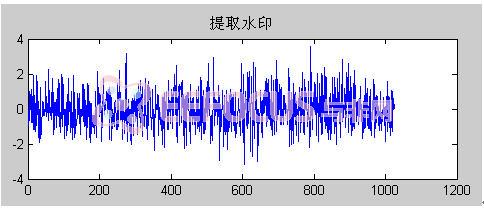
经过水印提取过程,得到提取出的水印为:
图10
(1)根据不可感知性的评价指标,我们选取了8位同学对我们嵌入水印后的图片进行了评价,结果为表13:
http://www.eefocus.com/fpga/329633/file:///C:UsersADMINI~1AppDataLocalTempmsohtmlclip1\01clip_image063.gif
| 1
| 2
| 3
| 4
| 5
| 6
| 7
| 8
|
良好
| 良好
| 良好
| 良好
| 一般
| 一般
| 一般
| 良好
|
表13
根据指标:优秀(5分,降质不可察觉)、良好(4分,降质可察觉,不让人厌烦)、一般(3分,降质轻微,让人厌烦)、差(2分,降质让人厌烦)、极差(1分,降质非常让人厌烦)来定义图像受损质量。则测试平均得分为:3.625,为良好等级,这说明原始图像的受损程度较小,基本不影响其视觉效果。
(2)根据鲁棒性评价指标,我们另外选取了8位同学对提取出的水印与原始水印进行比对,并给出评价,如表14:
http://www.eefocus.com/fpga/329633/file:///C:UsersADMINI~1AppDataLocalTempmsohtmlclip1\01clip_image063.gif
| 1
| 2
| 3
| 4
| 5
| 6
| 7
| 8
|
好
| 好
| 好
| 好
| 好
| 好
| 好
| 好
|
表14
根据指标:好(失真较小,能反映原始水印的信息),中(失真较大,但能基本反映原始水印的信息),差(失真大,不能反映原始水印的信息),来评价失真情况。
这充分说明我们提取出的水印效果很好,相对于原始水印,失真很小。结果是另人满意的。
6 总结
本文主要介绍了用硬件实现数字图像水印的过程,硬件中设计并充分利用了DCT模块与IDCT模块,采用流水工作方式使整个过程得以快速流畅的实现。
附录
II.源代码清单
硬件源代码清单
- dct.vhd
- idct.vhd
- mul_16.vhd
- part_mul.vhd
- adder_2.vhd
- adder_4.vhd
- adder_8.vhd.
- hwdct.vhd
- hw_idct.vhd
- lcd.vhd
软件源代码清单
1: lcd.h
2: lcd.c
3: hwdct.h
4: hwdct.c
5: hw_idct.h
6: hw_idct.c
7: test.c(board1上的主要代码)
8: pro.c(board2上的主要代码)
9: main.c(引导程序)
III:硬件原理图
Dct模块框图
系统总体连接框架
附录
I.源代码清单
硬件源代码清单
- dct.vhd
- idct.vhd
- mul_16.vhd
- part_mul.vhd
- adder_2.vhd
- adder_4.vhd
- adder_8.vhd.
- hwdct.vhd
- hw_idct.vhd
- lcd.vhd
软件源代码清单
1: lcd.h
2: lcd.c
3: hwdct.h
4: hwdct.c
5: hw_idct.h
6: hw_idct.c
7: test.c(board1上的主要代码)
8: pro.c(board2上的主要代码)
9: main.c(引导程序)
软件源代码主要函数:
Lcd模块:参考edk_flow里的设计,自己打包成头文件,主要函数有:
void XromMoveCursorHome();光标移至左上角
void XromMoveCursorLeft();光标左移
void XromMoveCursorRight();光标右移
void XromLCDOn();打开LCD
void XromLCDOff();关闭lcd
void XromLCDClear();显示清除
void XromLCDInit();初始化
void XromLCDSetLine(int line);光标移至某行
void XromLCDPrintChar(char c);打印字符
void XromLCDPrintString(char * line);在当前行打印字符串
void XromLCDPrint2Strings(char * line1, char * line2);打印字符串,显示在两行上
dct模块:
硬件设计为以64个数据为单位进行整体变化,故一次函数调用相应做一次8*8的变换。
hwdct(input_slot_id, output_slot_id, input_0, output_0):以input_0和output_0所指位置取64个数进行dct变换,input_0输入,output_0输出。
Idct模块:
与dct相似,函数为hw_idct(input_slot_id, output_slot_id, input_0, output_0)
通讯模块:采用rs232通讯,polled模式,以系统最大fifo的16byte为单位进行传输。
void send_16_bytes(){
int i;
u8 *p=send_data;
for(i=0;i<16;i++)
XUartLite_SendByte(XPAR_RS232_DCE_BASEADDR,*(p++));
}
send_16_bytes()用于board1向board2发数据。
void receive_16_bytes(){
int rx_count=0;
u8 rx_byte;
while(rx_count<16)
{
rx_byte = XUartLite_RecvByte(XPAR_RS232_DTE_BASEADDR);
recv_data[rx_count] = rx_byte;
rx_count++;
}
eceive_16_bytes()用于board2从board1收数据。
Flash模块:参考AVNET的设计,用其提供的sf_command进行flash的读写。
主要用到了:
void spi_transfer (unsigned char *send, unsigned char *recv, unsigned char num_bytes);
void SF_write_enable (Xuint32 BaseAddress);
void SF_write_disable (Xuint32 BaseAddress);
void SF_bulk_erase (Xuint32 BaseAddress);
void SF_sector_erase (Xuint32 BaseAddress, Xuint8 sector_address);
void SF_start_page_program (Xuint32 BaseAddress, Xuint8 sector_address, Xuint8 page_address, Xuint8 page_offset);
void SF_end_page_program (Xuint32 BaseAddress);
void SF_start_read (Xuint32 BaseAddress, Xuint8 sector_address, Xuint8 page_address,
Xuint8 page_offset, Xuint8 speed_setting);
void SF_end_read (Xuint32 BaseAddress);
主控制模块:board1完成大部分工作,其主程序为:
int main(){
XGpio led;
XGpio_Initialize (&led,XPAR_LEDS_8BIT_DEVICE_ID);
XromLCDInit();
XromLCDOn();
XromLCDClear();
int blocks_to_be_read;
int i,j,u,v;
int sigal_bytes_to_be_read;
Xint16 block_in[8][8];
Xint16 block_out[8][8];
Xint16 block_in_map[64];
Xint16 block_out_map[64];
Xint16 byte;
XUartLite RS232_DCE;
XUartLite_Initialize(&RS232_DCE, XPAR_RS232_DCE_DEVICE_ID);
XGpio dip;
XGpio_Initialize (&dip,XPAR_DIP_SWITCHES_4BIT_DEVICE_ID);
/////////read head information//////////////////////////////////////////
print("stage 1: reading file.......................\r\n");
XGpio_DiscreteWrite (&led,1,1);
print("input a file to be stored in ddrram\n\r");
XromLCDPrintString("stage1");
XromLCDSetLine(2);
XromLCDPrintString("reading file");
receive_8_bytes();
size_of_file=recv_data[5]*16777216+recv_data[4]*65536+recv_data[3]*256+recv_data[2];
receive_8_bytes();
offset=recv_data[5]*16777216+recv_data[4]*65536+recv_data[3]*256+recv_data[2];
blocks_to_be_read=offset/8-2;
sigal_bytes_to_be_read=offset-(blocks_to_be_read+2)*8;
///////////////pass away useless information/////////////////////////
for(i=0;i<blocks_to_be_read;i++)
receive_8_bytes();
for(i=0;i<sigal_bytes_to_be_read;i++)
byte=XUartLite_RecvByte(STDIN_BASEADDRESS);
////////////////read data section to global matrix/////////////////////
for(i=0;i<SIZE;i++)
for(j=0;j<SIZE;j+=8){
receive_8_bytes();
send_to_din(i,j);
}
print("OK!\r\n\n\n");
/////////////////////print file information//////////////////////////
print("stage 2: print file imformation.......................\r\n");
XGpio_DiscreteWrite (&led,1,3);
XromLCDClear();
XromLCDPrintString("stage2");
XromLCDSetLine(2);
XromLCDPrintString("print info");
xil_printf("size_of_file is %d bytes!\r\n",size_of_file);
xil_printf("data esction offsets of file is %d!\r\n",offset);
xil_printf("blocks_to_be_read is %d!\r\n",blocks_to_be_read);
xil_printf("sigal_bytes_to_be_read is %d!\r\n",sigal_bytes_to_be_read);
print("OK!\r\n\n\n");
///divide data to small blocks of 8*8 meanwhile performing dct//////
print("stage 3:dct performing...............................\r\n");
XGpio_DiscreteWrite (&led,1,7);
XromLCDClear();
XromLCDPrintString("stage3");
XromLCDSetLine(2);
XromLCDPrintString("perform dct");
for(i=0;i<SIZE/8;i++)
for(j=0;j<SIZE/8;j++){
for(u=0;u<8;u++)
for(v=0;v<8;v++){
block_in[v]=data_in[i*8+u][j*8+v]-128;
block_in_map[u*8+v]=block_in[v];
}
hwdct(input_slot_id,output_slot_id,block_in_map,block_out_map);
for(u=0;u<8;u++)
for(v=0;v<8;v++){
block_out[v]=block_out_map[u*8+v];
//data_out[i*8+u][j*8+v]=block_out[v];
data_out[i*8+u][j*8+v]=block_out[v];
}
}
print("OK!\r\n\n\n");
///////////embed warter mark//////////////////////////////////////
print("stage 4:warter mark performing...............................\r\n");
XGpio_DiscreteWrite (&led,1,15);
XromLCDClear();
XromLCDPrintString("stage4");
XromLCDSetLine(2);
XromLCDPrintString("warter mark");
for(i=0;i<SIZE/8;i++)
for(j=0;j<SIZE/8;j++)
data_out[i*8+3][j*8+3]=1.03;
print("OK!\r\n\n\n");
//////////stage5 :transfer header and dct data to board2////
print("stage 5 :transfering...............................\r\n");
XGpio_DiscreteWrite (&led,1,31);
XromLCDClear();
XromLCDPrintString("stage5");
XromLCDSetLine(2);
XromLCDPrintString("transfering");
u8 *p=data_out;
print("pluge com to board2,then push up dip 1 to begin transfer\r\n");
i=0;
while(i!=1)
i=XGpio_DiscreteRead (&dip,1);
for(i=0;i<LENGTH/8;i++){
for(j=0;j<16;j++){
*(send_data+j)=*(p++);
}
send_16_bytes();
}
i=0;
while(i!=3)
i=XGpio_DiscreteRead (&dip,1);
print("OK!/r/nmission on board 1 complete!");
/////////////////////complete///////////////////////////////////////
return 0;
}
}
II:硬件原理图
Dct模块框图
系统总体连接框架






 雷达卡
雷达卡
 发表于 2014-10-12 16:22:03
发表于 2014-10-12 16:22:03






 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 微信
微信 收藏
收藏 分享
分享 支持
支持 反对
反对 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 抢沙发
抢沙发 千斤顶
千斤顶 显身卡
显身卡