2.2 流水线
2.2.1 流水线的概念与原理
处理器按照一系列步骤来执行每一条指令。典型的步骤如下:
① 从存储器读取指令(fetch);
② 译码以鉴别它是属于哪一条指令(dec);
③ 从指令中提取指令的操作数(这些操作数往往存在于寄存器中)(reg);
④ 将操作数进行组合以得到结果或存储器地址(ALU);
⑤ 如果需要,则访问存储器以存储数据(mem);
⑥ 将结果写回到寄存器堆(res)。
并不是所有的指令都需要上述每一个步骤,但是,多数指令需要其中的多个步骤。这些步骤往往使用不同的硬件功能,例如,ALU可能只在第4步中用到。因此,如果一条指令不是在前一条指令结束之前就开始,那么在每一步骤内处理器只有少部分的硬件在使用。
有一种方法可以明显改善硬件资源的使用率和处理器的吞吐量,这就是当前一条指令结束之前就开始执行下一条指令,即通常所说的流水线(Pipeline)技术。流水线是RISC处理器执行指令时采用的机制。使用流水线,可在取下一条指令的同时译码和执行其他指令,从而加快执行的速度。可以把流水线看作是汽车生产线,每个阶段只完成专门的处理器任务。
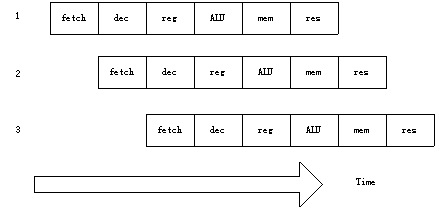
采用上述操作顺序,处理器可以这样来组织:当一条指令刚刚执行完步骤①并转向步骤②时,下一条指令就开始执行步骤①。图2.1说明了这个过程。从原理上说,这样的流水线应该比没有重叠的指令执行快6倍,但由于硬件结构本身的一些限制,实际情况会比理想状态差一些。
2.2.2 流水线的分类
从Acorn Computer公司在1983~1985年间开发的第一个3?m器件,到ARM公司在1990~1995年间开发的ARM6和ARM7,ARM整数处理器核的组织结构变化很小,这些处理器都是采用3级流水线,而这一时期CMOS工艺的发展,几乎将特征尺寸减少了一个数量级。因此,核的性能提高很快,但基本的操作原理大部分没有变化。
图2.1 流水线的指令执行过程
从1995年以来,ARM公司推出了几个新的ARM核。它们采用5级流水线和哈佛架构,获得了显著的高性能。例如,ARM9增加了存储器访问段和回写段,这使得ARM9的处理能力可达到平均1.1 Dhrystone1 MISP/MHz,与ARM7相比,指令吞吐量提高了约13%。

| 注意
| 在许多高性能处理器内部,一级Cache一般都设置有两个,其中,一个是指令Cache,另一个是数据Cache。这样可以减少取指令和读操作数的访问冲突,这种结构被称为哈佛架构。
把主存储器分成两个独立编址的存储器,一个专门存放指令,称为指令存储器,简称指存;另一个专门存放操作数,称为数据存储器,简称数存。两个存储器可以同时访问,这样就解决了取指令和读操作数的冲突。如果在此基础上规定在执行指令阶段产生的运算结果只写到通用寄存器中,不写到主存,那么取指令、分析指令和执行指令就可以同时进行。
|
ARM10更是把流水线增加到6级。ARM10的平均处理能力达到1.3 Dhrystone MISP/MHz,与ARM7相比,指令吞吐量提高了约34%。
![]()
| 注意
| 虽然ARM9和ARM10的流水线不同,但它们都使用了与ARM7相同的流水线执行机制,因此ARM7上的代码也可以在ARM9和ARM10上运行。
|
1.3级流水线ARM组织
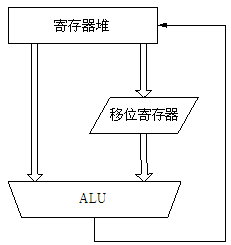
3级流水线ARM组织如图2.2所示,其主要的组成如下:
① 处理器状态寄存器堆(Rigister Bank)。它有两个读端口和一个写端口,每个端口都可以访问任意寄存器。另外还有附加的可以访问PC的一个读端口和一个写端口。
![]()
| 注意
| PC的附加写端口可以在取指地址增加后更新PC,读端口可以在数据地址发出之后从新开始取指。
|
② 桶形移位寄存器(Barrel Shifter)。它可以把一个操作数移位或循环移位任意位数。
③ ALU。完成指令集要求的算术或逻辑功能。
图2.2 3级流水线ARM的组织
④ 地址寄存器(Address Register)和增值器(Incrementer)。可选择和保存所用的存储器地址并在需要时产生顺序地址。
⑤ 数据输出寄存器(data-out register)和数据输入寄存器(data-in register)。用于保存传输到存储器和从存储器输出的数据。
⑥ 指令译码器和相关的控制逻辑(instruction decode and control)。
例2.1显示了一条单周期指令在流水线上的执行过程。
【例2.1】
ADD r1,r2
指令在流水线上的执行过程如图2.3所示。
图2.3 单周期指令在流水线上的执行过程
在ADD指令中,需要访问两个寄存器操作数,B总线上的数据移位后与A总线上的数据在ALU中组合,再将结果写回寄存器堆。在指令执行过程中,程序计数器的数据放在地址寄存器中,地址寄存器的数据送入增值器。然后将增值后的数据拷贝到寄存器堆的r15(程序计数器),同时还拷贝到地址寄存器,作为下一次取指的地址。
到ARM7为止的ARM处理器使用简单的3级流水线,包括下列流水线级:
· 取指(fetch):从寄存器装载一条指令。
· 译码(decode):识别被执行的指令,并为下一个周期准备数据通路的控制信号。在这一级,指令占有译码逻辑,不占用数据通路。
· 执行(excute):处理指令并将结果写回寄存器。
图2.4显示了3级流水线指令执行过程。
图2.4 3级流水线
![]()
| 注意
| 在任一时刻,可能有3种不同的指令占有这3级中的每一级,因此,每一级中的硬件必须能够独立操作。
|
当处理器执行简单的数据处理指令时,流水线使得平均每个时钟周期能完成1条指令。但1条指令需要3个时钟周期来完成,因此,有3个时钟周期的延时(latency),但吞吐率(throughput)是每个周期一条指令。例2.2通过一个简单的例子说明了流水线的机制。
【例2.2】
指令序列为:
ADD r1 r2
SUB r3 r2
CMP r1 r3
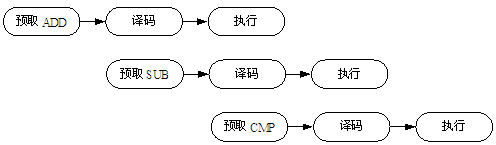
流水线指令序列如图2.5所示。
图2.5 流水线指令顺序
在第一个周期,内核从存储器取出指令ADD;在第二个周期,内核取出指令SUB,同时对ADD译码;在第三个周期,指令SUB和ADD都沿流水线移动,ADD被执行,而SUB被译码,同时又取出CMP指令。可以看出,流水线使得每个时钟周期都可以执行一条指令。
当执行多条指令时,流水线的执行不一定会如图2.5那么规则,图2.6显示了有STR指令的流水线状态。
图2.6 含有存储器访问指令的流水线状态
图2.6中在单周期指令ADD后出现了一条数据存储指令STR。访问主存储器的指令用阴影表示,可以看出在每个周期都使用了存储器。同样,在每一个周期也使用了数据通路。在执行周期、地址计算和数据传输周期,数据通路都是被占用的。在译码周期,译码逻辑负责产生下一周期用到的数据通路的控制信号。
![]()
| 注意
| 对于STR这种存储器访问指令,实际是在地址计算时由译码逻辑产生下一周期数据传输所需要的数据通路控制信号。
|
在图2.6中的指令序列中,处理器的每个逻辑单元在每个指令都是活动的。可以看出流水线的执行与存储器访问密切相关。存储器访问限制了程序执行必须花费的指令周期数。
ARM的流水线执行模式导致了一个结果,就是程序计数器PC(对使用者而言为r15)必须在当前指令执行前计数。例如,指令在其第一个周期为下下条指令取指,这就意味着PC必须指向当前指令的后8个字节(其后的第2条指令)。
当程序中必须用到PC时,程序员要特别注意这一点。大多数正常情况下,不用考虑这一点,它由汇编器或编译器自动处理这些细节。
例2.3显示了流水线下程序计数器PC的使用情况。
【例2.3】
指令序列为:
0x8000 LDR pc,[pc,#0]
0x8004 NOP
0x8008 DCD jumpAdress
当指令LDR处于执行阶段时,pc=address+8即0x8008。
2.5级流水线ARM组织
所有的处理器都要满足对高性能的要求。直到ARM7为止,在ARM核中使用的3级流水线的性价比是很高的。但是,为了得到更高的性能,需要重新考虑处理器的组织结构。执行一个给定的程序需要的时间由下式决定:
Tprog = (Ninst×CPI)/ fclk
式中:
Ninst:表示在程序中执行的ARM指令数;
CPI:表示每条指令的平均时钟周期;
fclk:表示处理器的时钟频率。
因为对给定程序(假设使用给定的优化集并用给定的编译器来编译)Ninst是常数,所以,仅有两种方法来提供性能。
第一,提高时钟频率。时钟频率的提高,必然引起指令执行周期的缩短,所以要求简化流水线每一级的逻辑,流水线的级数就要增加。
第二,减少每条指令的平均指令周期数CPI。这就要求重新考虑3级流水线ARM中多于1个流水线周期的实现方法,以便使其占有较少的周期,或者减少因指令相关造成的流水线停顿,也可以将两者结合起来。
3级流水线ARM核在每一个时钟周期都访问存储器,或者取指令,或者传输数据。只是抓紧存储器不用的几个周期来改善系统系统性能,效果是不明显的。为了改善CPI,存储器系统必须在每个时钟周期中给出多于一个的数据。方法是在每个时钟周期从单个存储器中给出多于32位数据,或者为指令或数据分别设置存储器。
基于以上原因,较高性能的ARM核使用了5级流水线,而且具有分开的指令和数据存储器。把指令的执行分割为5部分而不是3部分,进而可以使用更高的时钟频率,分开的指令和数据存储器使核的CPI明显减少。
![]()
| 注意
| 分开的指令和数据存储器。一般是分开的Cache连接到统一的指令和数据存储器上。
|
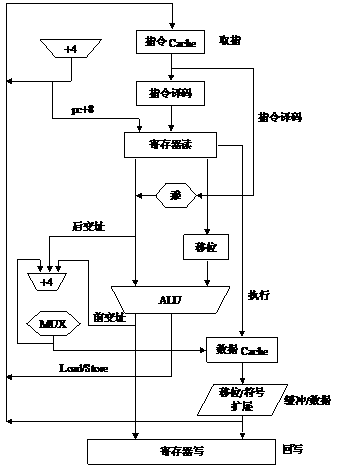
在ARM9TDMI中使用了典型的5级流水线。ARM9TDMI的组织结构如图2.7所示。
5级流水线包括下面的流水线级:
· 取指(fetch):从存储器中取出指令,并将其放入指令流水线。
· 译码(decode):指令被译码,从寄存器堆中读取寄存器操作数。在寄存器堆中有3个操作数读端口,因此,大多数ARM指令能在1个周期内读取其操作数。
· 执行(execute):将其中一个操作数移位,并在ALU中产生结果。如果指令是Load或Store指令,则在ALU中计算存储器的地址。
· 缓冲/数据(buffer/data):如果需要则访问数据存储器,否则ALU只是简单地缓冲一个时钟周期。
· 回写(write-back):将指令的结果回写到寄存器堆,包括任何从寄存器读出的数据。
图2.8显示了5级流水线指令的执行过程。
图2.7 5级流水线的组织结构
图2.8 5级流水线
在程序执行过程中,PC值是基于3级流水线操作特性的。5级流水线中提前1级来读取指令操作数,得到的值是不同的(PC+4而不是PC+8)。这产生的代码不兼容是不容许的。但5级流水线ARM完全仿真3级流水线的行为。在取指级增加的PC值被直接送到译码级的寄存器,穿过两极之间的流水线寄存器。下一条指令的PC+4等于当前指令的PC+8,因此,未使用额外的硬件便得到了正确的r15。
3.6级流水线ARM组织
在ARM10中,将流水线的级数增加到6级,使系统的平均处理能力达到了1.3Dhrystone MISP/MHz。图2.9显示了6级流水线上指令的执行过程。
图2.9 6级流水线
2.2.3 影响流水线性能的因素
1.互锁
在典型的程序处理过程中,经常会遇到这样的情形,即一条指令的结果被用做下一条指令的操作数。如例2.4所示。
【例2.4】
有如下指令序列:
LDR r0,[r0,#0]
ADD r0,r0,r1 ;在5级流水线上产生互锁
从例2.4中可以看出,流水线的操作产生中断,因为第一条指令的结果在第二条指令取数时还没有产生。第二条指令必须停止,直到结果产生为止。
2.跳转指令
跳转指令也会破坏流水线的行为,因为后续指令的取指步骤受到跳转目标计算的影响,因而必须推迟。但是,当跳转指令被译码时,在它被确认是跳转指令之前,后续的取指操作已经发生。这样一来,已经被预取进入流水线的指令不得不被丢弃。如果跳转目标的计算是在ALU阶段完成的,那么,在得到跳转目标之前已经有两条指令按原有指令流读取。
解决的办法是,如果有可能最好早一些计算转移目标,当然这需要硬件支持;如果转移指令具有固定格式,那么可以在解码阶段预测跳转目标,从而将跳转的执行时间减少到单个周期。但要注意,由于条件跳转与前一条指令的条件码结果有关,在这个流水线中,还会有条件转移的危险。
尽管有些技术可以减少这些流水线问题的影响,但是,不能完全消除这些困难。流水线级数越多,问题就越严重。对于相对简单的处理器,使用3~5级流水线效果最好。
显然,只有当所有指令都依照相似的步骤执行时,流水线的效率达到最高。如果处理器的指令非常复杂,每一条指令的行为都与下一条指令不同,那么就很难用流水线实现。 | 





 雷达卡
雷达卡
 发表于 2014-10-10 07:33:17
发表于 2014-10-10 07:33:17






 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 微信
微信 收藏
收藏 分享
分享 支持
支持 反对
反对 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 抢沙发
抢沙发 千斤顶
千斤顶 显身卡
显身卡