|
|
14.9 函数调用
函数设计的基本原则是使其函数体尽量的小。这样编译器可以对函数做更多的优化。
14.9.1 减少函数调用开销
ARM上的函数调用开销比非RISC体系结构上的调用开销小:
· 调用返回指令“BL”或“MOV pc,lr”一般只需要6个指令周期(ARM7上)。
· 在函数的入口和出口使用多寄存器加载/存储指令LDM和STM(Thumb指令使用PUSH和POP)提高函数体的执行效率。
ARM体系结构过程调用标准AAPCS定义了如何通过寄存器传递参数和返回值。函数中的前4个整型参数是通过ARM的前4个寄存器r0、r1、r2和r3来传递的。传递参数可以是与整型兼容的数据类型,如字符类型char、半字类型short等。
| 注意
| 如果是双字类型,如long long型,只能通过寄存器传递两个参数。
|
不能通过寄存器传递的参数,通过函数堆栈来传递。这样不论是函数的调用者还是被调用者都必须通过访问堆栈来访问参数,使程序的执行效率下降。
下面的例子显示了函数调用是传递4个参数和多于4个参数的区别。
传递4个参数的函数调用源文件如下。
int func1(int a, int b, int c, int d)
{
return a+b+c+d;
}
int caller1(void)
{
return func1(1,2,3,4);
}
编译的结果如下。
func1
ADD r0,r0,r1
ADD r0,r0,r2
ADD r0,r0,r3
MOV pc,lr
caller1
MOV r3,#4
MOV r2,#3
MOV r1,#2
MOV r0,#1
B func1
如果程序需要传递6个参数,变为如下形式。
int func2(int a, int b, int c, int d,int e,int f)
{
return a+b+c+d+e+f;
}
int caller2(void)
{
return func1(1,2,3,4,5,6);
}
则编译后的汇编文件如下。
func2
STR lr, [sp,#-4]!
ADD r0,r0,r1
ADD r0,r0,r2
ADD r0,r0,r3
LDMIB sp,{r12,r14}
ADD r0,r0,r12
ADD r0,r0,r14
LDR pc,{sp},#4
caller2
STMFD sp!,{r2,r3,lr}
MOV r3,#6
MOV r2,#5
STMIA sp,{r2,r3}
MOV r3,#4
MOV r2,#3
MOV r1,#2
MOV r0,#1
BL func2
LDMFD sp!,{r2,r3,pc}
综上所述,为了在程序中高效的调用函数,最好遵循以下规则。
· 尽量限制函数的参数,不要超过4个,这样函数调用的效率会更高。
· 当传递的参数超过4个时,要将多个相关参数组织在一个结构体中,用传递结构体指针来代替多个参数。
· 避免将传递的参数定义为long long型,因为传递一个long long型的数据将会占用两个32位寄存器。
· 函数中存在浮点运算时,避免使用double型参数。
14.9.2 使用__value_in_regs返回结构体
编译选项__value_in_regs指示编译器在整数寄存器中返回4个整数字的结构或者在浮点寄存器中返回4个浮点型或双精度型值,而不使用存储器。
下面的例子显示了__value_in_regs选项的用法。
typedef struct { int hi; uint lo; } int64; // 注意该结构中,高位为有符号整数,低位为无符号整数
__value_in_regs int64 add64(int64 x, int64 y)
{ int64 res;
res.lo = x.lo + y.lo;
res.hi = x.hi + y.hi;
if (res.lo < y.lo) res.hi++; // carry from low word
return res;
}
void test(void)
{ int64 a, b, c, sum;
a.hi = 0x00000000; a.lo = 0xF0000000;
b.hi = 0x00000001; b.lo = 0x10000001;
sum = add64(a, b);
c.hi = 0x00000002; c.lo = 0xFFFFFFFF;
sum = add64(sum, c);
}
编译后的结果如下所示。
add64
ADDS a2,a2,a4
ADC a1,a3,a1
MOV pc,lr
test
STMDB sp!,{lr}
MOV a1,#0
MOV a2,#&f0000000
MOV a3,#1
MOV a4,#&10000001
BL add64
MOV a3,#2
MVN a4,#0
LDMIA sp!,{lr}
B add64
当使用__value_in_regs定义结构体时,编译的代码大小为52字节,如果不使用__value_in_regs选项,则编译出的结果为160字节(本书中没有列出未使用__value_in_regs时的编译结果,读者有兴趣可以自己上机试验)。
14.9.3 叶子函数
所谓叶子函数(leaf function)就是在其函数体内不存在对其他函数调用,它也常被称为终级函数。因为叶子函数不需要调用其他函数,所有没有保存/恢复寄存器的操作,因此执行效率比一般函数要高。
当函数中必须对一些寄存器进行保存时,可以使用高效率的多寄存器存储指令STM,对需要保存的寄存器内存一次性存储。
正是由于叶子函数执行的高效性,所以在编程时,尽量将子程序编写为叶子函数,这样即使程序中多次调用也不会影响代码性能。
为了高效的调用函数,可以遵循下面函数调用原则。
· 避免在被频繁调用的函数中调用其他函数,以保证被频繁调用的函数被编译器编译为叶子函数。
· 把比较小的被调用函数和调用函数放在同一个源文件中,并且要先定义后调用,编译器就可以优化函数调用或内联较小的函数。
· 对性能影响较大的重要函数可使用关键字_inline进行内联。
14.9.4 嵌套优化
| 注意
| 嵌套优化(Tail-Call optimization)只适用于armcc。编译时如果使用-g或-debug选项,编译器自动关闭该功能。
|
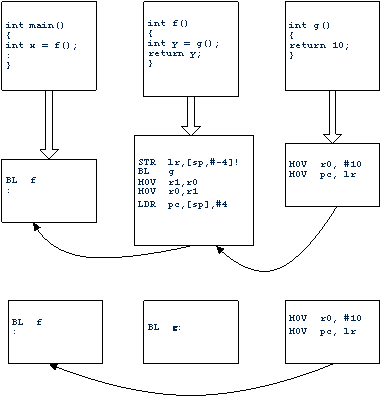
一个函数如果在其结束时调用了另一个函数,则编译器使用B指令调转到被调用函数,而非BL指令。这样就避免了一级不必要的函数返回。图14.3显示了嵌套优化的调用过程。
图14.3 嵌套优化函数调用过程
当编译时使用-O1或-O2选项时,编译器都执行这种嵌套优化。需要注意的是,当函数中引用了局部变量地址,由于指针别名问题的影响,即使函数在返回时调用了其他函数,编译器也不会使用嵌套优化。
下面通过一个例子来分析嵌套优化是如何提高代码执行效率的。
extern int func2(int);
int func1 (int a, int b)
{ if (a > b)
return (func2(a - b));
else
return (func2(b - a));
}
编译后的代码如下所示。
func1
CMP a1,a2
SUBLE a1,a2,a1
SUBGT a1,a1,a2
B func2
首先,func1中使用B指令代替BL指令,不用担心lr寄存器被破坏,减少了对寄存器压栈保护操作。另外,程序直接从func2返回到调用func1的函数,减少一次函数返回。如果说正常的指令调用过程为:
BL + BL+ MOV pc,lr + MOV pc,lr
那么经过嵌套优化的函数调用过程就可以表示为:
BL + BL+ MOV pc,lr
这样,总的开销将减少25%。
14.9.5 单纯子函数
所谓单纯子函数(Pure Functions)是指那些函数返回值只和调用参数有关。换句话说,就是如果调用函数的参数相同,那么函数的返回结果也相同。如果程序中存在这样的函数,可以在函数定义时使用_pure进行声明,这样在程序编译时编译器会根据函数的调用情况对其进行优化。
下面的例子显示了当函数用_pure声明时,编译器对其所做的优化。
程序源码文件如下。
int square(int x)
{
return x * x;
}
int f(int n)
{
return square(n) + square(n)
}
编译后的结果如下。
square
MOV a2,a1
MUL a1,a2,a2
MOV pc,lr
f
STMDB sp!,{lr}
MOV a3,a1
BL square
MOV a4,a1
MOV a1,a3
BL square
ADD a1,a4,a1
LDMIA sp!,{pc}
上面的程序中,square函数为“单纯子函数”,当使用_pure声明该函数时编译器在调用该函数时,将对程序进行优化。
声明的方法和编译后的结果如下所示。
__pure int square(int x)
{
return x * x;
}
f
STMDB sp!,{lr}
BL square
MOV a1,a1,LSL #1
LDMIA sp!,{pc}
从编译后的代码中可以看到,用_pure声明的函数在f函数中只调用了一次。
虽然“单纯子函数”可以提高代码执行效率,但同时也会带来一些负面影响。比如,在“单纯子函数”中,不能直接或间接访问内存地址。所以在程序中使用“单纯子函数”时要特别小心。
另外,还可以使用#pragma声明“单纯子函数”,下面的代码显示了它的声明过程。
#pragma no_side_effects
/* function definition */
#pragma side_effects
14.9.6 内嵌函数
ARM编译器支持函数内嵌功能。使用关键字“_inline”声明函数,可以使函数内嵌。下面的例子显示了如何使用函数内嵌功能。
程序源文件如下。
__inline int square(int x)
{
return x * x;
}
#include <math.h>
double length(int x, int y)
{
return sqrt(square(x) + square(y));
}
编译结果如下所示。
length
STMDB sp!,{lr}
MUL a3,a1,a1
MLA a1,a2,a2,a3
BL _dflt
LDMIA sp!,{lr}
B sqrt
使用函数内嵌有以下好处:
· 减少了函数调用开销(如寄存器的压栈保护);
· 减少了参数传递开销;
· 进一步提高了编译器对代码优化的可能性(如编译器可将ADD和MUL指令合并为一条MLA指令)。
但使用函数内嵌将增加代码尺寸。也正是处于这种原因,armcc和tcc都没有提供函数自动内嵌的编译选项。
一般来说,只有对性能影响较大的重要函数才使用关键字_inline进行内嵌。
14.9.7 函数定义
使用函数时要先定义后调用是ARM编程的基本规则之一。在函数调用之前定义函数,编译器可以检查被调用函数的寄存器使用情况,从而对其进行进一步的优化。
首先来看下面的例子。
int square(int x);
int sumsquares1(int x, int y)
{
return square(x) + square(y);
}
/* square函数可以在本文件中定义,也可以在其他源文件中定义 */
int square(int x)
{
return x * x;
}
int sumsquares2(int x, int y)
{
return square(x) + square(y);
}
编译的结果如下所示。
sumsquares1
STMDB sp!,{v1,v2,lr}
MOV v1,a2
BL square
MOV v2,a1
MOV a1,v1
BL square
ADD a1,v2,a1
LDMIA sp!,{v1,v2,pc}
square
MOV a2,a1
MUL a1,a2,a2
MOV pc,lr
sumsquares2
STMDB sp!,{lr}
MOV a3,a2
BL square
MOV a4,a1
MOV a1,a3
BL square
ADD a1,a4,a1
LDMIA sp!,{pc}
从编译的结果可以看出,将square函数定义放在sumsquares函数前,编译器可以判断寄存器a3和a4并未使用,所有在调用函数入口处并未将其压栈。这样,减少了内存访问,提高了代码执行效率。 |
|






 雷达卡
雷达卡
 发表于 2014-10-10 07:23:40
发表于 2014-10-10 07:23:40

 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 微信
微信 收藏
收藏 分享
分享 支持
支持 反对
反对 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 抢沙发
抢沙发 千斤顶
千斤顶 显身卡
显身卡