|
|
一、应用前景
在低中频(f <1.5kHz)情况下,双耳时间差是定位的主要因素,这时对固定频率的声音,双耳时间差与双耳相位差是相对应的。然而对于更高的频率,虽然双耳时间差的概念依然正确,但双耳相位差的概念将变得模糊不清。以正弦声音为例来进行解释,设双耳时间差的最大值为Δtmax,则角频率为ω的正弦声音在左、右两耳产生的相位差为ΔΦ = ωΔtmax。可以看出,当ω较小时,声音频率较低,波长较长,由时间差所造成的相位差有确定的意义,双耳可以根据它来判定声源的方位;当ω较大时,即声音频率较高、波长较短时,由时间差所形成的相位差数值将较大,甚至会超过180°,使人不能判断是超前还是滞后,因而失去了作为声源定位因素的意义。所以双耳相位差只对低频声的方位判断起主要作用,而双耳时间差(严格说是群延时)则可作为1.5~4.0kHz的一个定位因素。
另外一方面,人头对入射声波起到了阻碍作用,导致了两耳信号间的声级差(interaural intensity difference,IID)。声级差除与入射声波的水平方位角有关外,还与入射声波的频率有关。在低频时,声音波长大于人头尺寸,声音可以绕射过人头而使双耳信号没有明显的声级差。随着频率的增加,波长越来越短,头部对声波产生的阻碍越来越大,使得双耳信号间的声级差越来越明显——这就是我们常说的人头遮蔽效应。对于1.5~4.0kHz的频率范围来说,声级差和时间差是声源定位的共同因素,而当f > 5.0kHz时,双耳声级差是定位的主要因素,与时间差形成互补。总的来说,双耳时间差和声级差涵盖了整个声音频率范围。
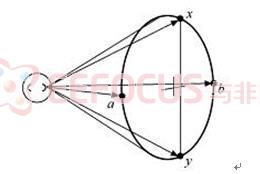
但是如果只考虑双耳时间差和声级差两个因素,还不足以完全解释定位问题,其中最典型的问题就是前后镜像声源的定位。假设人头是一个球体,不存在外耳,如图3所示,水平方位角为θ的声源和水平方位角为180°.θ的镜像声源在人耳处会产生相同的IID和ITD。对于实际的人头来说,虽然IID和ITD不会完全相同,但是它们会在很大程度上相似。当只考虑双耳时间差和声级差时,就会产生前后镜像声源的混淆,其实这只是空间锥形区域声像混淆(cones of confusion)的一种特例。为了解决这个问题,就要依赖于其他的因素进行声源定位了。
图3 空间锥形区域声像混淆
2.3 耳郭效应
在听觉系统中用于对声源进行垂直定位的因素通常被认为是“单耳信号”。耳郭具有不规则的形状,形成一个共振腔。当声波到达耳郭时,一部分声波直接进入耳道,另一部分则经过耳郭反射后才进入耳道。由于声音到达的方向不同,反射声和直达声之间强度比不仅发生变化,而且反射声与直达声之间在不同频率上产生不同的时间差和相位差,使反射声与直达声在鼓膜处形成一种与声源方向位置有关的频谱特性,听觉神经据此判断声音的空间方向。耳郭效应的本质就是改变不同空间方向声音的频谱特性,也就是说人类听觉系统功能上相当于梳状滤波器,将不同空间方向的声音进行不同的滤波。
频谱特性的改变主要是针对于高频信号,由于高频信号波长短,经耳郭折向耳道的各个反射波之间会出现同相相加、反相相减,甚至相互抵消的干涉现象,形成频谱上的峰谷,也即耳郭对高频声波起到了梳状滤波作用。
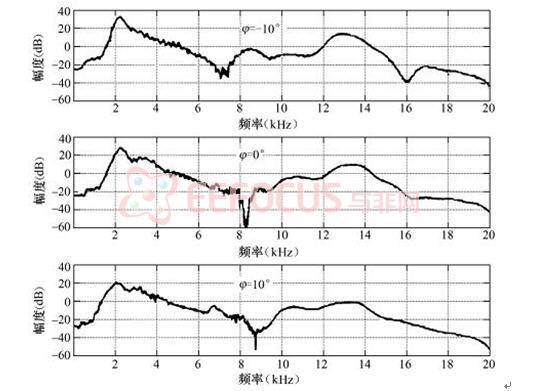
耳郭效应对声源的垂直定位起到很重要的作用。图4显示的是声源位于中垂面,仰角φ分别为.10°、0°和10°在人头模型上测得的耳郭响应曲线。由图可以看出,在高频处响应曲线变化比较大,因此可以对声源进行定位。例如对位于前后镜像的声源进行定位时,虽然位于(r , θ , φ)的声源和位于(r , 180°.θ , .φ)的镜像声源会在人耳处产生极相似的ITD和IID,但是可以通过耳郭效应对声源作精确定位。
图4 人头模型测量的耳郭效应
耳郭效应进行声音定位,主要是将每次接收到的声音与过去存储在大脑里的重复声排列或梳状波动记忆进行比较,然后判断定位。因每个人耳郭尺寸不同,所以每个人在大脑中存储的记忆是不同的,这一点应引起注意。
2.4 人头转动因素
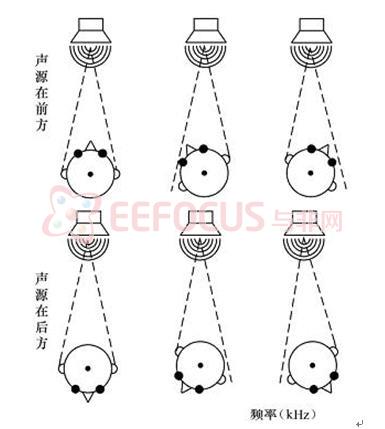
如图5所示在低频或较差的听音环境中,当双耳效应和耳郭效应对声源的定位不能给出明确的信息时,听音者会转动头部来消除不确定性。最经常使用这种方法的情况是出现空间锥形区域声像混淆现象时,因为这样会造成不确定的双耳效应。
图5 头部转动避免声源位置前后混淆
2.5 优先效应
声音的定位除了以上因素外还有其他因素。在混响环境中,优先效应起到重要作用。它是心理声学的特性之一。所谓的优先效应是指当同一声源的直达声和反射声被人耳听到时,听音者会将声源定位在直达声传来的方向上,因为直达声会首先到达人耳处,即使反射声的强度比直达声高达10dB。因此,声源可以在空间中进行正确的定位,而与来自不同方向的反射声无关。但是优先效应不会完全消除反射声的影响。反射声可以增加声音的空间感和响度感。
当优先效应用在混响环境中识别语音时,就产生了哈斯效应(Haas effect)。哈斯观察到,只要早期反射声到达人耳足够早就不会影响语音的识别,相反,由于增加了语音的强度,还会有利于语音的识别。而且哈斯发现,相对于音乐来说,语音对反射延时时间和混响的变化更为敏感。对于语言声来说,只有滞后直达声50ms以上的延迟声才会对语音的识别造成影响。所以50ms被称为哈斯效应的最大延时量。在哈斯的平衡实验证明,当延时为10~20ms时,先导声会对滞后声有最大程度的抑制。
以上说明,只是对虚拟环绕声的简单介绍,更详细的介绍参见附见。
3.DSP音频处理器结构说明
由于本系统的音频处理器主要以一款现在的音频处理器为参考进行开发,故对音频处理器只作简单说明。
如图6所示
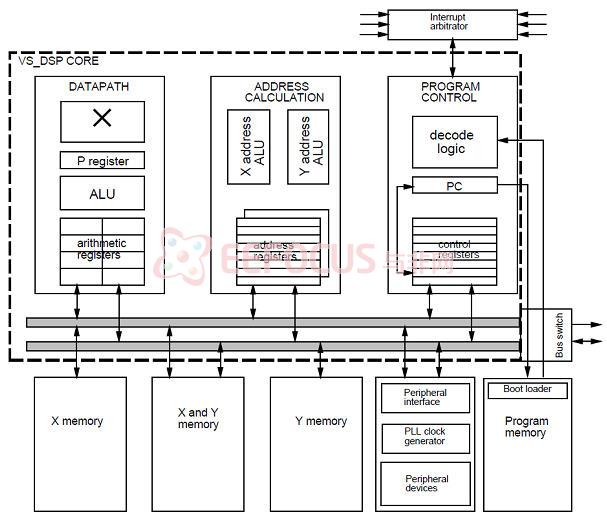
图6 音频DSP处理器结构
图示为一款商用DSP核的结构,区别于普通MCU处理器的是其采用了典型的哈佛结构,存储部分配置了X,Y,XY等部分,以适合于音频处理,至于数据通路和普通处理器相比区别不大,故考虑以移植为主。
五、实现目标
利用数字信号处理技术对数字滤波器的设计进行改进,主要对传递函数零极点处理;
采用Matlab进行原理性的仿真实验,验证滤波器效果和算法的正确性;
使用VerilogHDL硬件描述语言进行电路建模,划分好电路模块,分模块予以实现,最终实现整个IP核;
用ModelSim对IP Core进行硬件仿真,验证电路的正确性以及是否具备优化空间;
在Xilinx的Vertex系列或是Spartan系列FPGA上予以验证;
对整个3D虚拟环绕声系统进行主观综合评价。 |
|






 雷达卡
雷达卡
 发表于 2014-10-12 16:22:49
发表于 2014-10-12 16:22:49

 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 微信
微信 收藏
收藏 分享
分享 支持
支持 反对
反对 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 抢沙发
抢沙发 千斤顶
千斤顶 显身卡
显身卡