摘要
网络编码改变了传统网络节点上路由器交换和交换机对信息流“存储—转发”的模式,提出网络路由交换节点对输入的信息流编码后再发送,并在接收器上进行解码,从而还原信息。随着网络编码理论的日益发展和完善,其应用的研究也越来越受到重视。
本文首先介绍网络编码理论的基本概念,回顾了近年来网络编码的研究动态。接着指出研究多信源网络编码组播通信的重要性,在使用NetFPGA开发平台的基础上,提出网络编码组播通信系统及其整体设计方案。在方案中重点介绍了硬件系统中采用的编码策略—随机线性编码,解码策略、算法以及通信协议,同时介绍了系统的软硬件接口和软件作用。最后,给出了编码路由器、转发路由器以及解码路由器三个系统的详细设计方案,方案中主要包括单元模块图,每个模块的主要功能与结构,数据处理流程及算法说明,输入输出信号及说明、关键时序或状态。
由于本系统的主要功能是由硬件实现,所以和传统组播通信网络相比,具有时延小,没有了调度和排队时间,使得网络中链路负载更均衡,体现出了网络编码的优势。
1 网络编码理论及相关研究应用背景
1.1网络编码理论产生背景和基本概念
60年前C.E.Shannon发表“通信数学原理“解决了信道容量极限问题。2000年诞生的网络编码(Network Coding:NC)是继此后的一个全新突破,它解决了网络通信中单/多源对多接收点组/广播如何达到网络容量极限的问题。传统网络通信节点上的路由交换机只完成存储转发功能。NC指出如果允许路由交换机对输入信息流进行编码再发送,使得网络节点既实现路由功能又实现编码功能。在这种全新的体系结构下,网络性能可以达到最大流传输的理论极限[1][2]。
2000年,以香港中文大学信息工程系为主的研究人员针对通讯网络的瓶颈问题,提出了一种看似疯狂的想法,这种具有革命潜力的方法名为网络编码,以网络编码器取代路由器;原本只是单纯的传送信息的路由器,换成编码器之后,传送的却是有关信息的证据,而不是信息本身;当接收器收到证据时,即可结合各项线索,推导出原始信息。[3]
《科学美国人》杂志(Scientific American Magazine)2007年6月,以“Breaking Network Logjams”(打破网络僵局)为题刊登了MIT科学家详细介绍了7年前诞生于香港中文大学的网络编码理论[4]。其中指出,网络编码是继60年前C.E.Shannon发表“通信的数学原理”后,网络通信理论的一个全新突破。C.E.Shannon解决了点对点信道的容量极限问题,而NC解决了如何达到单源对多点及多源对多点的网络通信容量极限的问题[4]。传统网络通信理论把信息流当成管道中流动的水,是不可压缩的;故传统网络节点上的路由交换机只是完成存储转发功能。NC理论的划时代意义在于:提出网络路由交换节点对输入的信息流进行编码再发送,可进一步提升网络吞吐量!从而改变了比特不能再被压缩的经典结论,指出网络信息流可以被压缩。
网络编码最简单的概念来自‘蝴蝶网’,如图1.1-1所示:
图1.1-1 网络编码的基本原理
上图所示的网络中,源节点S1想把信息流ai传送给R1和R2。另一方面,源节点S2也希望在相同时间、以相同速度,把信息流bi传送给同样的接收节点R1和R2。假设每个路径每秒可携带一个位元,而且只能顺着箭号所指的方向前进。如果路由器只传输其所接收到的信息,那么中间链路将是个瓶颈,因为每秒总共接收到二位元的资料,但其容量只有一位元,路由器每秒只能传送一位元资料给中间链路,这种瓶颈会造成可怕的塞车。相反,如果把一般的路由器换成编码器,它可以把两个信息通过异或或者线性组合运算成单一位元输送给中间链路,并且发送ai+bi (或者ai和bi的任意线性组合),这样就轻而易举地解决了塞车问题[3][5]。
网络编码另一个与路由系统不同之处在于,充分利用网络资源。图1中,S1透过路径S1R1把ai传给R1,S2透过路径S2R2把bi传给R2,这在路由系统中是不会使用到的。节点R1接收到ai,并且根据每次编码器运算结果,输入到与编码器使用的相同函数(异或或者线性组合)内,推导出bi。节点R2解出ai也是同样的道理。重复对每个位元字串进行相同的流程,最后就能得出两个原始信息。
可见,有了网络编码,网络的运作可望变得更有效率(不需要增加硬件设备或频宽,就可以提高网络吞吐量),可以改善网络的负载均衡,节省网络带宽消耗,节省无线网络的能量消耗,提高了网络的鲁棒性,同时对于具有链路时延的网络,相对于路由方式,通过网络编码进行多播传输时可以获得较小的传播时延[6][7]。
随后,李硕彦等在证明了在足够大的有限域内,通过节点内进行线性网络编码(Linear Network Coding: LNC)就可以达到网络组播,广播等的理论上限[8]。在线性范围内解决达到理论上界的问题为NC进入实际应用奠定了坚实的基础。随后,Yueng,李硕彦[9]等出版了国际上第一本网络编码理论专著“Network Coding Theory”。
Koetter等[10]于2003年提出将NC问题与多项式方程建立数学联系,使得讨论NC问题又多了一种有力的数学工具代数理论;LNC针对于已经了解整个网络拓扑状况的情况下,经过网络路由设定,通过确定的矩阵计算公式对报文进行编解码,实现简单,但适应性和容错性较差。论文[11]中提出随机网络编码概念(Random Network Coding:RNC),与线性编码结合在一起,使得分布式的、简单实用的网络编码体系形成。随机线性网络编码是一种分布式算法,编码在有限域上进行,系数随机选取,其灵活性远大于LNC。
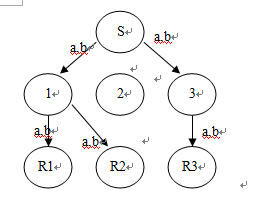
下面给出一个不仅NC提高多播网络吞吐量,而且显著改善网络负载均衡的例子。图1.1-2(a)显示了网络的容量,所有的边的容量都是2。在这个例子中,最大流是4。图2(b), (c)和(d)分别显示了单会话IP组播,多会话IP组播和基于网络编码的组播的分配树。在图2(b)中,发送端通过一个组播分配树同时向接收端R1, R2和R3发送了两个比特a,b。在图2(c)中,组播会话1,2和3分别向接收者发送了比特a,b和c。需要指出的是多会话IP组播所有的会话不是拥有同一个分配树。在图2(d)中,发送端同时向接收端R1, R2和R3发送了四个比特a,b,c和d[12]。
所有的组播技术中网络编码可以达到最高的吞吐量,因为它可以最大流发送信息。我们看到在图2(b), (c)和(d)中在单位时间内接收端分别接收到2,3和4比特。因此在这个例子中,基于网络编码的组播的吞吐量是单会话IP组播的2倍,多会话IP组播的1.3倍。
通过比较基于网络编码的组播和现在的组播来研究负载均衡的影响。假定基于网络编码的组播使用图2(d)例子中的容量的一半。在这种情况下,单会话IP组播和网络编码都在单位时间内向所有的接收端发送了2比特。在图2(b)中,通过了网络中9条链路(总共发送10比特)中的5条来传输2比特,另外4条没有使用。另一方面,当网络编码使用时,2( d) 通过了9条链路(总共发送9比特)来传输2比特。于是通过应用网络编码,流量负载可以分散在整个网络上。
(a)链接容量 (b)单会话的IP组播
(c)多会话的IP组播 (d)网络编码组播
图1.1-2 网络编码提高网络容量,同时均衡了网络流量
1.2国内外研究动态与现状
网络编码自诞生以来,普及性的急速增长就连其奠基者也始料未及。从2005年开始每年一次的NetCod workshop 得到了Microsoft, Qualcomm等机构的资助。短短几年,发表了几百篇学术论文。这个崭新的领域对许多相关学科产生了深远的影响,NC的理论研究范围包括信息论及通信的几乎每个领域,如线性编码,非线性编码,随机编码,静态码,卷积码,群码,Alphabet码,码构建,算法协议,有环网络,无向网络,链路失效及其网络管理,分离理论,错误检测和纠错码,密码学,多信源编码,多-单播编码, Cost Criteria, 非均匀需求,关联信源编码,最大流/刮集界,叠加编码,网络互连,路由寻找,无线及卫星网络,Ad hoc网络,传感网络,数据存储及分布,矩阵理论,复杂性理论,图论,随机图论,树装箱(Tree Packing),多种物流(Multicommodity flow),游戏理论,矩阵胚理论(Matriod theory),信息论不等式,排队论分析,率失真(rate-distortion)可逆网络,多用户信道,联合网络信道编码,P2P网络等[13]。
国外多所著名大学如普林斯顿大学、麻省理工、瑞士EPFL 学院等和多家IT 公司的研究中心,包括微软研究院、贝尔实验室、AT &T 的香农信息实验室等都在积极开展对网络编码理论和应用的研究。与此同时,网络编码的实际应用问题被提到技术研究的前线。从2005年第一届Net Cod国际会议上就明确将NC在现实通信中的应用作为研究的重点。微软公司是最早开展网络编码应用研究的公司[14],Microsoft公司已经采用网络编码作为其下一代网络内容发布平台Avalanche的核心技术。
不仅国外,近两年来国内学者也开始研究网络编码。清华大学[15],西安电子科大、及电子科技大学[16],北京邮电大学[17]均投入了NC与无线网络方面的研究。NC在P2P网络传输,流媒体广播及内容分发方面的应用方面,上海大学[18]、湖南大学[19]和并行与分布处理国家重点实验室[20],中国科学技术大学[21]等都进行了研究。最近几年中,网络编码在组播通信方面的应用成为了研究的热点,复旦大学研究了单信源组播并提出了一项关于在目前internet路由器上实现网络编码的专利[23],西安电子科技大学提出了一种基于网络编码的组播路由算法,能够大大降低网络资源消耗,同时能改善负载均衡[24]。
以上网络编码在通信中的应用研究基本上都是处于理论和计算机软件仿真阶段,在用硬件平台搭建实际的组播网络,并在真实的网络环境中应用网络编码,进行其实现的复杂度和网络性能的评估等方面的研究尚处于起步阶段。
2 多信源组播系统结构及整体设计方案
2.1项目研究需求、目标和内容
网络编码能够提高网络吞吐量,提升鲁棒性、安全性等网络性能。具有网络编码功能的路由器是未来网络发展的趋势。组播通信在网络通信中有重要的作用,事实上,任何一个网络都可以认为是组播网的一个特例。然而,目前在世界上研究网络编码在组播上的应用大多集中在单信源组播方面,例如,单信源多信宿网络如何达到最大传输速率问题[25],基于网络编码的组播路由算法和性能评估[26], 基于网络编码的组播通信网络的拓扑设计[27], 多信源随机线性网络编码在组播通信的研究[28]以及单信源组播网中编码节点的研究[29],以上研究都是以软件仿真为主,没有形成实际的硬件平台和系统。
多信源组播的应用非常广泛,如P2P内容分发网络等。事实上,任何一个网络都可以作为多信源组播的一个特例,因此研究多信源组播是有意义且必要的。
本项目的主要研究目标是基于网络编码的多信源组播系统的实现。在基于国内外网络编码理论在组播通信中的最新研究成果和技术,对网络编码理论进行深入学习和探讨,提出一种基于网络编码的多信源组播系统和网络,然后依据此系统设计出可实现组播的通信协议和相关算法,再利用开放式的网络设计硬件平台NetFPGA[30],使提出的协议和算法在硬件上实现,最后在实际的环境中用若干电脑和NetFPGA组成一个小型组播通信网络进行系统测试和性能评估。
2.2 NetFPGA——新一代开放式网络研究平台简介
由斯坦福大学开发的NetFPGA是一个基于Linux操作系统的可重用开放性硬件平台,允许用户在实验室内搭建高性能的网络模型进行仿真和研究。它具有以下特点[31]:
(1)很好地支持模块化设计,它可以使研究人员在硬件上搭建Gb/s高性能网络系统模型。(2)NetFPGA是一个基于Linux系统的开放性平台,可以利用平台上现有的资源,在前人开发的基础上添加自己的模块和修改现有的系统,而不需要重复地搭建外围模块、开发驱动和GUI等,大大减轻了网络研究的任务。
NetFPGA的硬件主要包含了4个1Gb/s的以太网接口(GigE),一个用户可编程的FPGA,以及两片SRAM和一片DRAM。NetFPGA开发板通过标准的PCI总线接口连接到PC机或服务器,模块框图如图2.2-1所示。
图 2.2-1:NetFPGA平台的组成框图
在外部硬件接口方面,除了连接PC主机的PCI总线插口,一个Broadcom公司的物理层收发器(PHY)包含了四个千兆位以太网接口,板子上的两个SATA连接口使得系统内部的多个NetFPGA可以通过SATA数据线连接起来,互相之间直接以很高的速度交换数据,而不必再通过PCI总线。NetFPGA通过PCI总线与主机CPU连接,提供了硬件加速的数据通道,分担CPU的处理任务。主机CPU按照DMA方式读写NetFPGA上的寄存器和存储器来配置NetFPGA的工作模式,并对NetFPGA的工作状态进行监控。
NetFPGA平台的软件系统包括操作系统、作为软件接口的驱动程序、实现各种硬件功能的逻辑代码、执行控制功能的软件程序、系统测试的脚本程序,以及计算机辅助设计软件工具。
2.3 利用NetFPGA实现本设计的总体构想
基于网络编码的组播通信系统将充分运用NetFPGA上面的各种硬件和软件资源,实现系统的设计目标,具体是:(1)根据项目的需求,合理且充分利用NetFPGA卡上面的各种硬件资源,如FPGA、存储芯片和输入输出接口;(2)由于基于NetFPGA实现的IPv4原理性路由器是一个开源的系统,因此我们可以运用其提供的部分代码和已经设计好的底层硬件平台,来帮助我们实现设计目标。例如,我们的系统的编码、解码工作主要在网络层完成,因此我们可以利用NetFPGA中已有的物理层、MAC层硬件逻辑来实现数据的接收和发送;(3)在软件方面,由于NetFPGA平台选择了CentOS操作系统,并且开发了软硬件接口的驱动程序,基于Linux内核的设备驱动程序和Java程序开发的图形用户界面(Java GUI)等,因此我们可以对其应用、改进,使我们的系统更加完善,方便调试和后续的进一步研究。
2.4系统实现的整体设计方案说明
2.4.1 系统拓扑图及说明
如图2.4-1所示,是拟采用的组播通信网络的拓扑图:
图2.4-1基于网络编码组播的网络拓扑图
说明:为了易于在工程上实现,将网络编码路由器分为编码路由器EC(Encoding router)和解码路由器DC(Decoding router),分别专门负责编码和解码。具体讲,如图1所示,信源S1,S2,S3发送数据包,编码路由器EC0和EC1负责将接收到的数据包以随机的系数进行线性编码后发送给组播路由器R,注意,这里的组播路由器更准确地说是转发路由器,因为它的功能只是将收到的数据包转发到其三个输出端口,而没有IGMP(组播管理)和相应的组播路由功能。当然,我们也可以直接在EC上实现转发的功能,增加R的原因是考虑到NetFPGA端口数量的限制(每块NetFPGA只有4个端口)。解码路由器DC接收编码的数据并解码,并将它发送给下游的信宿主机,在这里,由于PC数量的限制,我们使用双口网卡可以将解码路由器和信宿放到同一台主机上,这对网络性能的测试和实现没有任何影响。
2.4.2编码策略与方案
作为一种编码结构的提出,我们将编码只限于不同信源数据包之间,暂不考虑信源包内部编码。相同信源的数据包之间分“代”,以便在解码时区分信息先后顺序[32]。不同信源的包之间不区分代的概念。
定义:为了讨论的方便性和简洁性,我们将信源S1的第1代记为S(1,1),信源S2的第3代记为S(2,3),……依此类推。依据包头和缓存,每个信源的代的编号从0开始,至1023结束,即信源n的最大的代编号为S(n,1023)
在编码路由器EC上对不同信源的IP数据包进行编码,编码系数矢量随机选择,编码方法是线性编码。例如,在上图中的编码路由器EC0,设两个链路的输入的全局编码向量为:in(e)=
 ,
,
由于只有两个信源之间的编码有且只有一条边输出,则本地编码向量为(α β),依据文章[33]的公式:
则输出out(e)=(α β)
=αS(1,x)+βS(2,y)。编码后的数据以NCP(network coding protocol)包头封装,然后再封装在IP数据报中,如图2.4-2所示:
http://www.eefocus.com/communication/335311/file:///C:UsersADMINI~1AppDataLocalTempmsohtmlclip1\01clip_image021.gifhttp://www.eefocus.com/communication/335311/file:///C:UsersADMINI~1AppDataLocalTempmsohtmlclip1\01clip_image021.gif
图2.4-2:编码后数据的封装格式
为减小相应的编码负担和提高编码效率,我们只对网络中的IP数据报中的有效载荷进行编码(已经编码过的数据包可以再进行编码),不对ARP等其他数据包编码。在编码路由器中,我们为不同的输入通道开辟不同的FIFO以进行顺序存取和编码,编码流程如图2.4-3所示:
图2.4-3:数据包的编码流程
2.4.3随机系数的选择
根据相关资料可知,随即编码系数矢量的选择可以从Galois Field中进行选择,依据论文[33][34],我们选择域为GF256,即
,此时可以解码的概率为1-=0.996,这个概率可以满足大多数的应用需求。
2.4.4 NCP数据包头的格式
为了能够在解码路由器上进行解码,我们需要在被编码的有效载荷前增加NCP数据包头[35],根据我们的方案,其包头格式如图2.4-4:
版本
4位
| 首部长度
4位
| 总长度
16位)
| 标志
2位
| 保留
6位
| 第1个包信源号
| 第2个包信源号
| ……
| ……
|
|
|
| 第8个包信源号
| 第1个包的填充长度(10位)
| 编码系数矢量1
(8位)
| 代的编号(10位)
| 编码次数
(4位)
| 第2个包的填充长度
| 编码系数矢量2
| 代的编号
| 编码次数
| ………………
| ……
| ……
|
| 第n个包的填充长度
| 编码系数n
| 代的编号
| 编码次数
| 编码后的有效载荷
| | | | | | | | | | | | | | | |
0 3 7 23 25 31
图2.4-4:NCP数据包的包头格式
先将包头各个字段的含义说明如下:
①版本:NCP数据包格式的版本,为了后续开发研究和以前版本的区分,第一个版本为0001.
②首部长度和总长度:首部长度是指除了有效数据载荷以外的部分,共4位,单位是4字节,其最小值为2。当首部长度为3时,意味着该包的载荷没有被编码,只是加了包头。当其值大于3时,其值减去3为被编码的信源数。
总长度是之首部长度和有效载荷之和的长度,16位,单位为字节。
③标志:若进入编码路由器的只是一个没有编码过的IP数据包时,不进行编码,直接将包头前2行加在原IP数据包的有效载荷的前面即可。当仅有一个NCP数据包进入编码路由器时,我们不进行编码,直接进行转发,如图2.4-5所示:
有效载荷的数据包类型
| 标志位
| 没有编码的IP数据包
| 01
| 编码后的NCP数据包
| 10
| 保留
| 00
| 保留
| 11
|
图2.4-5:标志位的含义
④编码次数:即从原始数据包算起,被编码的次数,因为在一个实际的网络中,数据的编码可以是递归的,即可以多次被编码。有时,只有一个数据源时,直接在其前面加上NCP包头而不进行编码。增加编码次数是为了能够在多次编码后进行解码。若编码前数据包为IP数据包,其编码次数为0,若为NCP数据包,则次数≥1.当一个IP数据包和一个已编码的数据包编码时,利用编码次数,可以避免解码路由器将NCP数据包误以为IP数据包而交给主机。
⑤第一个包的填充长度:因为不同数据源的数据包的长度可能不一样,为了便于编码计算,将它们前位补0使得长度一致。由于一个典型的以太网数据包的长度在500~1500字节之间,所以填充长度不超过1000字节。另外,我们还要考虑MAC层的最大传送单元(MTU)的限制,即编码后的MAC帧的长度不能超过1518字节。由此可以计算出,被编码的数据包的最大长度是1499字节
⑥编码系数:即随机选择的编码矢量的系数,是在一个GF256的有限域中随机选择。
⑦代的编号:即被编码的数据包的代的编号,是按照顺序产生的编号,目的是方便解码。
⑧包的信源号:4位,对进入编码路由器的数据包的信源进行编号,其目的是为了方便解码,在我们目前的体系中,最多允许8个数据包同时被编码。注意:当信源数少于8个时,例如有3个,则分别将对应的数据包的信源号分别填为0000,0001,0010,其余的都填写为1111。
2.4.5 转发(组播)路由器R工作流程
在实际的应用中,R应该是具有组播功能的路由器,即可以运行网际组播管理协议IGMP和多播路由选择协议DVMRP等,从而它可以知道网络的局部的拓扑和满足组播成员的要求。为了初期容易实现,我们将其功能简化为转发功能(即广播功能)。
2.4.6数据包的解码
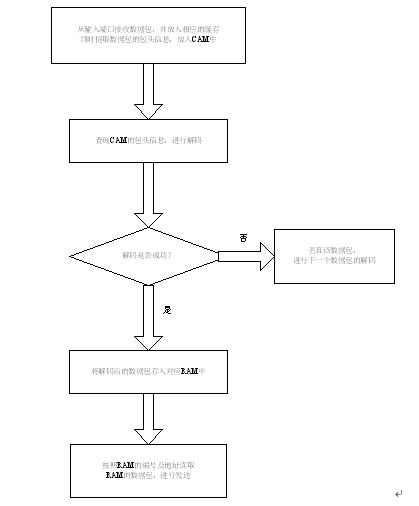
(1) 高速缓存和CAM的使用
数据包的解码由DC解码路由器完成。每个解码路由器DC有三个输入通道,分别连接到R0,R1,R2其解码的策略是:我们先在DC中开辟三块不同的高速缓存(DRAM)和与之分别对应的3个CAM,它们分别对应于R0、R1、R2,缓存和CAM的大小为代的编号的大小,即http://www.eefocus.com/communication/335311/file:///C:UsersADMINI~1AppDataLocalTempmsohtmlclip1\01clip_image030.gif=1024,在这三个缓存中存放按照顺序接收到的数据。根据前面的数据处理过程,显然,对应于每个缓存中的数据,虽然有的是真正编码后的数据包,有的只是在IP数据包前增加了一个包头,但我们都可以认为是NCP数据包。在将数据存入高速缓存的同时,提取NCP数据包头中的信源号和代的编号,将它们存入到内容可寻址存储器CAM(content addressable memory),则CAM的输出即为对应数据在高速缓存的地址。
使用CAM的原因是:由于经过编码,以及网络环境非理想,解码路由器收到的encoded packet可能是乱序的。因此考虑使用CAM做检索链接,以便快速寻址当前解码所需要的packet。
(2) 解码顺序
根据实际情况的考虑,目前有两种解码的顺序,一种情况是按照信源号和代的编号的顺序进行解码,第二种情况是按照缓存及其缓存地址的顺序来解码。
在已知网络拓扑的情况下,我们按照信源号和代的编号的顺序来进行解码,即对于信源采用轮询策略,对于内部代的编号采用小数优先策略。例如,在我们的拓扑图中,解码顺序是:S(1,1),S(2,1),S(3,1)→S(1,2),S(2,2),S(3,2)→……S(1,n),S(2,n),S(3,n)……。
在未知网络拓扑的情况下,我们按照高速缓存的地址顺序来进行解码,即先对高速缓存采用轮询策略,对每个缓存中,采用地址由小到大的顺序进行解码,如图2.4-7所示,进行解码的顺序是PZ1
→PX1→ PY1→ PZ2→ PX2→PY2→PZ3……
高速缓存1 高速缓存2 高速缓存3
地址 数据包 地址 数据包 地址 数据
01 PZ1 01 PX1 01 PY1
02 PZ2 02 PX2 02 PY2
03 PZ3 03 PX3 03 PY3
04 …… 04 …… 04 ……
……
图2.4-7 按照高速缓存的地址顺序来进行解码
上面的两种解码方式各有优点:在一般情况下,按照信源号和代的编号的顺序来进行解码可获得较高的解码速率,但在网络环境恶化的情况下,其丢包率(无法解码的概率)会比第2中方案高一些。由于在我们已有的网络环境一般较好,为了体现网络编码的传输的高效性,我们按照第1种顺序进行解码。
(3) 解码流程
为了避免高速缓存的写数据溢出,我们将设置二级缓存,二级缓存也有3个,可用SRAM构造,将SRAM分为3块地址上独立的区域,每个SRAM 大小为256×1800bytes,分别对应不同的信源,我们将解码后的数据,根据其代的编号,分别暂存在对应SRAM的对应地址上。例如,将S(1,1)存储在SRAM1的第1个地址空间,S(2,4)则存储在SRAM2的第4个地址空间。每个RAM各有1个读、写指针,可以同时按顺序读写数据,按照地址由小到大的顺序读出的数据被发送到输出队列中。
如图2.4-8所示为数据包的解码过程,每个告诉缓存各有1个读、写指针,在解码过程中,读取缓存是按照解码的顺序进行的,而在写缓存是按地址顺序写的。
图2.4-8:数据包解码流程
(4) 解码策略与方法
我们按照信源号和代的编号的顺序来进行解码,即对于信源采用轮询策略,对于内部代的编号采用小数优先策略。例如,在我们的拓扑图中,解码顺序是:S(1,1),S(2,1),S(3,1)→S(1,2),S(2,2),S(3,2)→……S(1,n), S(2,n), S(3,n)……
假定我们按照上述顺序准备解码S(1,x),解码程序如图9:
图2.4-9 数据包S(1,x)的解码过程
无法求解一个数据包的原因可能是:该数据包由于延迟或者丢失,在CAM中搜寻不到,再有就是线性相关,无法解出来。在我们的系统中,由于其拓扑的特殊性,没有线性相关的情况,因此无法解码的情况只发生在解码因子丢失的情况下。
解码子任务:解码子任务的输入是包头信息,由调用它的程序给出,输出有两个变量:解码后的数据包和解码标志,解码标志告诉调用它的程序是否可以解码,我们假定现在要对S(i,j)解码,子任务流程如图2.4-10:
图2.4-10:解码子任务流程
(5) 解码后数据包暂存SRAM的读写策略
我们将解码后的数据包暂存在SRAM中等待发送,每个信源对应一个SRAM区域,同一个信源的解码后的人数据包存储在同一个RAM中,存储地址为该包的代的编号。每个RAM各有一个读指针,写数据按照RAM的地址大小顺序写入。读数据时按照信源编号和代的大小读取。由于发送速率一般会高于解码速率,因此RAM不用很大,暂定为256×1800。
每读取一个数据后,指针加1,若读取某个SRAM时无数据(可能是延迟或丢失造成),则不用等待,直接进行下一个SRAM的读取,3次轮询之后还没有到达,则强行加读指针加1,读取下一个数据包。如图2.4-11所示为SRAM的读写操作。
图2.4-11 二级缓存SRAM的读写操作
(6)举例说明
为了更清楚地显示整个解码的操作过程,我们以DC3为例,图2.4-12显示的是DC3的3个高速缓存和CAM,解码过程如下
图2.4-12 数据包S(1,x)解码过程
数据包S(1,x)解码过程如下:
先将S(1,x)的包头3个CAM中搜索,在CAM1中得到索引为00,我们利用该索引得到S(1,x)在高速缓存1的地址为00,从高速缓存1读取数据,得到a S(1,x)+b S(2,y),为了求解S(1,x)我们调用解码子任务先求解S(2,y),为了防止出现死循环,解码子任务只在CAM2和CAM3中搜寻S(2,y),在CAM2中得到地址为02,于是读取高速缓存2的02地址数据,得到eS(2,y)+f S(3,z),于是再调用子任务求解S(3,z),在CAM3中搜索S(3,z)后解出S(3,z), 于是可以解出S(2,y),最后再解出S(1,x),同时,分别将S(3,z)、 S(2,y) 、S(1,x)存入SRAM3,SRAM2,SRAM1相应的地址中。
2.5 系统软硬件接口及相关软件功能
在系统中,并非只有硬件逻辑在不同的模块之间处理数据包,而且还有相应的软件和控制程序。如图2.5-1所示,是数据包在系统中的通道与处理流程。数据在系统中的通道分为data bus和register bus,data bus主要进行数据的硬件处理,register bus则是软硬件的接口。在数据传输的每个阶段对软件应该是可控的、透明的,这些软件在更高层次上执行更复杂的算法和协议,或者处理一些异常情况,同时,对于系统开发人员,也应该是可控的,因为开发人员往往需要配置和调试硬件。使用通用的寄存器接口就可以使数据处理对软件透明化,这是靠映射内部的硬件寄存器来完成的,即所谓的存储映射技术。对于软件来讲,映射寄存器相当于一个I/O接口,它可以由软件访问和修改。
图2.5-1:系统中的register bus 和data bus
Register bus中每个模块的register连接在一起,组成一个信息环路。这些register块中存储了数据处理在每个模块中的状态和阶段,任何一个模块都可以响应来自PCI总线寄存器的访问和控制要求,而PCI总线寄存器可以通过软件来控制。也就是说,硬件和软件的通信是通过PCI总线完成的。
数据以及控信息在硬件和主机系统之间是通过PCI总线传输的,以Linux网络存储栈作为接口的。NetFPGA向主机发送分组数据的过程如图2.5-2a所示:
- 分组到达,发往CPU队列;
- 中断程序通知驱动程序有分组到达;
- 驱动程序设置和初始化DMA传送器;
- NetFPGA通过DMA总线发送分组;
- 中断程序发送DMA结束信号;
- 驱动程序把分组传递到网络存储栈;
图2.5-2a:NetFPGA向主机发送数据 图2.5-2b:主机向NetFPGA发送数据
主机向NetFPGA发送分组数据的过程如图2.5-2b所示:
- 控制软件通过网络socket发送分组,分组被递交给驱动程序;
- 驱动程序设置和初始化DMA传送器;
- 中断程序发送DMA结束信号;
主机访问寄存器是通过系统调用系统内核的ioctl( )函数作为接口的。读写寄存器的操作函数如下,这两个函数内部调用了ioctl( )函数。
readReg(nf2device *dev, int address, unsigned *rd_data)
writeReg(nf2device *dev, int address, unsigned *wr_data)
例如: readReg(&nf2, OQ_NUM_PKTS_STORED_0, &val);
主机访问NetFPGA寄存器的过程如下:
(1)控制软件调用ioctl( )函数操作网络socket,由函数ioctl传递给驱动程序;
(2)驱动程序完成PCI寄存器的读写;
3 系统的详细设计方案
3.1 概述
在组播网络的拓扑图中,编码路由器、转发路由器和解码路由器是三个独立的系统,各自完成编码、转发和解码的任务。前面讲过,分组的编码、解码主要在网络层完成。在网络层中数据通道中,data bus和ctrl bus是同步传输的,二者之间的关系和格式如图3.1-1所示:
| ctrl bus(8位)
| Data bus(64位)
| | ff
| module header
| | 00
| Pkt data1
| | 00
| ……
| | xy(xy≠00)
| Last pkt data
|
图3.1-1 数据通道中的data bus和ctrl bus
Ctrl为ff时,表明为一个数据包的包头,xy为非零数据,指明最后一个有效的字节所在的位置,如01000000指明是第7个,即data[63:48]为有效数据。模块之间数据传输的过程是:若上一个模块已经处理完毕,想把数据传输到下一个模块,首先判断输入信号rdy是否有效,当rdy = 1时,将数据和控制信号同步发送出去,同时wr_vld信号有效,时序如图3.1-2所示:
图3.1-2 有效的数据传输时序
3.2 编码路由器详细设计方案
3.2.1编码系统整体模块如图3.2-1所示
图3.2-1:编码系统整体模块图
3.2.2系统中各单元模块的功能与时序
(1)Input arbiter
① Input arbiter内部结构如图3.2-2所示:
图3.2-2 Input arbiter内部结构图
② 本模块输入输出信号列表及说明
Signal name
| Bit width
| Input or output
| description
| Input_fifo_data_1
| 64
| input
| Input data bus from “input FIFO 1”
| Input_fifo_ctrl_1
| 8
| input
| Input ctrl bus from “input FIFO 1”
| Input_fifo_empty_1
| 1
| input
| 1=input FIFO is empty,0=otherwise
| Input_fifo_rd_en_1
| 1
| output
| Read enable
| Input_fifo_data_2
| 64
| input
| Input data bus from “input FIFO 2”
| Input_fifo_ctrl_2
| 8
| input
| Input ctrl bus from “input FIFO 2”
| Input_fifo_empty_2
| 1
| input
| 1=input FIFO is empty,0=otherwise
| Input_fifo_rd_en_2
| 1
| output
| Read enable
| Data_arbiter_ctrl_1
| 64
| output
| Output data bus to “control module”
| Ctrl_arbiter_ctrl_1
| 8
| Output
| Output ctrl bus to “control module”
| Val_arbitrer_ctrl_1
| 1
| Output
| 1=data from input arbiter 1 to head splitter 1 is valid, 0=otherwise
| Rdy_arbiter_ctrl_1
| 1
| Input
| 1=module “head splitter 1” is ready to receive
| Data_arbiter_ctrl_2
| 64
| output
| Output data bus to “control module”
| Ctrl_arbiter_ctrl_2
| 8
| Output
| Output ctrl bus to “control module”
| Val_arbitrer_ctrl_2
| 1
| Output
| 1=data from input arbiter 2 to head splitter 2 is valid, 0=otherwise
| Rdy_arbiter_ctrl_2
| 1
| Input
| 1=module “head splitter 2” is ready to receive, 0=otherwise
| Data_arbiter_out_1
| 64
| output
| Output data bus to “output arbiter module”
| Ctrl_arbiter_out_1
| 8
| Output
| Output ctrl bus to “output arbiter module”
| Val_arbiter_out_1
| 1
| Output
| 1=data from input arbiter 1 to output arbiter is valid, 0=otherwise
| Rdy_arbiter_out_1
| 1
| Input
| 1=module “output arbiter” is ready to receive from input arbiter 1, 0=otherwise
| Data_arbiter_out_2
| 64
| output
| Output data bus to “output arbiter module”
| Ctrl_arbiter_out_2
| 8
| Output
| Output ctrl bus to “output arbiter module”
| Val_arbiter_out_2
| 1
| Output
| 1=data from input arbiter 2 to output arbiter is valid, 0=otherwise
| Rdy_arbiter_out_2
| 1
| Input
| 1=module “output arbiter” is ready to receive from input arbiter 2, 0=otherwise
| clk
| 1
| Input
| System clock, running at 125MHz
| Rst_n
| 1
| input
| System asynchronous reset signal
|
<div style="clear:both;">
③ 本模块输入输出信号列表及说明
Signal name
| Bit width
| Input or output
| description
| Data_arbiter_ctrl_1
| 64
| Input
| Input data bus from “input arbiter 1”
| Ctrl_arbiter_ctrl_1
| 8
| Input
| Input ctrl bus from “input arbiter 1”
| Val_arbiter_ctrl_1
| 1
| Input
| 1=data from input arbiter 1 to head splitter 1 is valid, 0=otherwise
| Rdy_arbiter_ctrl_1
| 1
| output
| 1=module “head splitter 1” is ready to receive from input arbiter 1, 0=otherwise
| Data_arbiter_ctrl_2
| 64
| Input
| Input data bus from “input arbiter 2”
| Ctrl_arbiter_ctrl_2
| 8
| Input
| Input ctrl bus from “input arbiter 2”
| Val_arbiter_ctrl_2
| 1
| Input
| 1=data from input arbiter 2 to head splitter 2 is valid, 0=otherwise
| Rdy_arbiter_ctrl_2
| 1
| output
| 1=module “head splitter 2” is ready to receive from input arbiter 2, 0=otherwise
| Data_payloadfifo_router_1
| 64
| output
| output data bus to “payload router”
| Ctrl_payloadfifo_router_1
| 8
| output
| Output ctrl bus to “payload router”
| Rd_en_payloadfifo_router_1
| 1
| Input
| Read enable
| Empty_payloadfifo_router_1
| 1
| output
| 1=FIFO ctil payload 1 is empty,0=otherwise
| Data_payloadfifo_router_2
| 64
| output
| output data bus to “payload router”
| Ctrl_payloadfifo_router_2
| 8
| output
| Output ctrl bus to “payload router”
| Rd_en_payloadfifo_router_2
| 1
| Input
| Read enable
| Empty_payloadfifo_router_2
| 1
| output
| 1=FIFO ctrl payload 2 is empty,0=otherwise
| Data_center_legacyfifo_1
| 64
| Output
| Output data bus to “packing center”
| Rd_en_center_legacyfifo_1
| 1
| Input
| Read enable
| Data_center_packingfifo_1
| 14
| Output
| Output data bus to “packing center”
| Rd_en_center_packingfifo_1
| 1
| input
| Read enable
| Data_center_legacyfifo_2
| 64
| Output
| Output data bus to “packing center”
| Rd_en_center_legacyfifo_2
| 1
| Input
| Read enable
| Data_center_packingfifo_2
| 14
| Output
| Output data bus to “packing center”
| Rd_en_center_packingfifo_2
| 1
| input
| Read enable
| clk
| 1
| input
| System clock, running at 125MHz
| Rst_n
| 1
| input
| System asynchronous reset signal
|
<div style="clear:both;"> 3、Coding
① 子模块列表
Submodule name
| quantity
| description
| Payload router
| 1
| Determine by the arrival of packets from both channels, whether should process coding or transport directly to packing module
| M64×8 multiplier
| 2
| Multiply 64-bit data from “payload router” by 8-bit random number from “prng tap16”
| Prng tap16
| 1
| 8-bit random number generator
| M72×72 adder
| 1
| 72-bit by 72-bit full adder
| M72to64 converter
| 1
| Convert data bus width from 72-bit to 64-bit
|
<div style="clear:both;"> ④ 功能描述及数据流
本模块为封装模块。子模块packing FIFO构建与coding模块的数据接口,将接收并缓存编码数据包以及未编码数据包(使用额外第64位数据标志该包是否编码,该位为“1”说明编码,该位为“0”说明未编码)。
子模块packing center是主封装模块。它根据packing FIFO中读出的数据判断需要哪些包头信息,然后向control模块中相应FIFO读取需要的包头信息,并依次封装成NCP数据包,发送到output arbiter。
⑤ 关键时序及状态机
第一层状态机:packing_center_status
图3 .2-9 packing_center_status状态机
第二层状态机:
图3 .2-10coded_process状态机
图3.2-11 uncoded_process 状态机
5、Output arbiter
① 本模块输入输出信号列表及说明
Signal name
| Bit width
| Input or output
| Description
| Out_data_out_0
| 64
| input
| input data bus from “packing center”
| Out_ctrl_out_0
| 8
| Input
| input ctrl bus from “packing center”
| Data_val_out_0
| 1
| Input
| 1=data from packing center to output arbiter is valid, 0=otherwise
| Rdy_out_0
| 1
| output
| 1=output arbiter is ready to receive from packing center, 0=otherwise
| Out_data_out_1
| 64
| input
| input data bus from “input arbiter 1”
| Out_ctrl_out_1
| 8
| Input
| input ctrl bus from “input arbiter 1”
| Data_val_out_1
| 1
| Input
| 1=data from input arbiter 1 to output arbiter is valid, 0=otherwise
| Rdy_out_1
| 1
| output
| 1=output arbiter is ready to receive from input arbiter 1, 0=otherwise
| Out_data_out_2
| 64
| input
| input data bus from “input arbiter 2”
| Out_ctrl_out_2
| 8
| Input
| input ctrl bus from “input arbiter 2”
| Data_val_out_2
| 1
| Input
| 1=data from input arbiter 2 to output arbiter is valid, 0=otherwise
| Rdy_out_2
| 1
| output
| 1=output arbiter is ready to receive from input arbiter 2, 0=otherwise
| Out_data_mac
| 64
| output
| output data bus to “MAC Layer”
| Out_ctrl_mac
| 8
| Output
| output ctrl bus to “MAC Layer”
| Data_val_mac
| 1
| Output
| 1=data from output arbiter to MAC layer is valid, 0=otherwise
| Rdy_mac
| 1
| Input
| 1=MAC layer is ready to receive from output arbiter, 0=otherwise
| clk
| 1
| Input
| System clock running at 125MHz
| Rst_n
| 1
| input
| System asynchronous reset signal
|
<div style="clear:both;">
3.4.2系统中各单元模块的功能与时序
1、Input_arbiter:采用轮询策略,当fifo非空时从fifo接收数据,根据mac header判断数据是否为IP数据包,若是,则将数据发送到DRAM读写控制模块,同时将信源号、代编号发送到CAM读写控制模块。
可用一个两状态的状态机实现:即轮询判断输入和数据输出:在FIFO非空时读数据,并根据数据包的类型发送到DRAM读写控制器或output fifo中,若是IP数据包,同时将信源号、代编号发送给CAM读写控制。
主要信号列表:
信号名称
| 位宽 bit
| I/O
| 描述
| Wr_vld_arb
| 1
|
| 写DRAM控制器有效
| Out_data_0
| 64
|
| 输出至DRAM的data
| Out_ctrl_0
| 8
|
| 输出至DRAM德ctrl
| Src_gen_seq
| 24
|
| 信源号、代的编号
| Cam_vld
| 1
|
| 写CAM控制器有效
| Port_num_dram
| 2
|
| 数据的接收端口号
| Out_data_1
| 64
|
| 输出至output arbiter的data
| Out_ctrl_1
| 8
|
| 输出至output arbiter的ctrl
| Wr_vld_1
| 1
|
| 输出至output arbiter信号有效
|
2、output_arbiter
图3.4-2 output_arbiter结构图
本模块的结构如图3.4-2所示,由两个输入fifo和一个输出仲裁器组成,两个fifo缓存来自SRAM和input_arbiter的数据包,Output_arbiter的作用是将解码后的数据发送到MAC层。由于对于非IP数据包我们并没有对其进行编码,所以在解码路由器中由input_arbiter判断后直接输出output_arbiter;对于编码后的IP数据包,在解码后先暂存到SRAM中,再发送出去。本模块就是轮流判断并接收来自SRAM和input_arbiter的数据,并将数据包发送到MAC层。
输入输出信号列表:
信号名称
| 位宽bits
| I/O
| 描述
| out_data_3
| 64
| O
| 输出至MAC层的数据总线
| out_ctrl_3
| 8
| O
| 输出至MAC层的控制总线
| out_wr_3
| 1
| O
| 输出有效
| out_rdy_3
| 1
| I
| MAC层空闲标志
| dcod_data_0
| 64
| I
| 已经解码的IP数据包的数据总线
| dcod_ctrl_0
| 8
| I
| 已经解码的IP数据包的控制总线
| wr_vld_0
| 1
| I
| 写有效
| wr_rdy_0
| 1
| O
| 接收数据空闲标志
| non_ip_data
| 64
| I
| 非IP数据包数据总线
| non_ip_ctrl
| 8
| I
| 非IP数据包控制总线
| wr_vld_1
| 1
| I
| 写有效
| wr_rdy_1
| 1
| O
| 接收数据空闲标志
|
3、decoded_reg_grp
本模块分别与decode_control_panel,decoder和SRAM_contrl相连接,主要作用是记录信源的某代数据包是否已经解码,并将相应的解码信息输出给其他模块,模块结构如图3.4-3:
图3.4-3:decoded_reg_grp模块图
端口列表:
信号名称
| 位宽bits
| I/O
| 描述
| rd_dcod_reg_req_0
| 1
| I
| 读取解码标志位请求
| rd_dcod_src_gen_0
| 12
| I
| 要读取的数据包的信源号和代编号
| req_ack_vld_0
| 1
| O
| 输出有效
| alredy_decod_0
| 1
| O
| 解码标志(“1”代表已经解码,“0”代表未解码)
| rd_dcod_reg_req_1
| 1
| I
| 读取解码标志位请求
| rd_dcod_src_gen_1
| 12
| I
| 要读取的数据包的信源号和代编号
| req_ack_vld_1
| 1
| O
| 输出有效
| alredy_decod_1
| 1
| O
| 解码标志(为1时代表已经解码,为0时未解码)
| set_req
| 1
| I
| 置位请求
| set_src_gen
| 12
| I
| 需要置位的数据包(表示已经解码完毕)
| set_info_vld
| 1
| I
| 置位信息有效
| set_ack
| 1
| O
| 置位请求响应
| reset_req
| 1
| I
| 复位请求
| reset_src_gen
| 12
| I
| 需要复位的数据包(表示解码后已发送完毕)
| reset_info_vld
| 1
| I
| 复位信息有效
| reset_ack
| 1
| O
| 复位请求响应
|
① 读解码标志
当decoder模块或decode_control_panel读取解码标志时,将查询结果输出,alredy_decod_0和alredy_decod_1为“1”时表示本次查询的数据包已经解码,为“0”时表示未被解码,以与decoder接口为例,读取解码标志的时序如图3.4-4:
图3.4-4:读解码标志位时序图
② 写解码标志位
当decoder把一个数据包解码成功后,就把相应的解码标志位置1,当SRAM_control将一个数据包发送出去后,再将相应的解码标志位置0,以置位为例,解码标志位的写时序如图3.4-5:
图3.4-5:置位解码标志寄存器
4、DRAM控制器:接收数据,并顺序存储到DRAM中去。
注意:我们将DRAM分为三块,分别对应于数据接收的三个信道,即第0个信道的数据存储到DRAM的第0块,第1个信道的数据存储到DRAM的第1块……信道号由port_num给出。由于DRAM是按照block读写的,因此每个block大小为2034字节,位宽为144位。
图3.4-6:DRAM控制器模块图
① DRAM控制器与DRAM的接口与读写时序:
Signal Group
| Signal Name
| Direction
| Bits
| Description
| Request Negotiation
| p_wr_req
| from user logic to block-of-data rd/wr module
| 1
| 1=request for write transfer (data are from user logic to DRAM), 0=otherwise
| Request Negotiation
| p_wr_ptr
| from user logic to block-of-data rd/wr module
| PKT_MEM_PTR_WIDTH
| the start address of DRAM for transfer. Each unit is 16-byte piece
| Request Negotiation
| p_wr_ack
| from block-of-data rd/wr module to user logic
| 1
| 1=the arbiter acknowledges that the write requester can proceed, 0=otherwise
| Data Transfer
| p_wr_data_vld
| from user logic to block-of-data rd/wr module
| 1
| 1=the write data is valid, 0=otherwise
| Data Transfer
| p_wr_data
| from user logic to block-of-data rd/wr module
| PKT_DATA_WIDTH
| the data transferred from user logic to DRAM
| Data Transfer
| p_wr_full
| from block-of-data rd/wr module to user logic
| 1
| 1=notify the user logic to pause transfer the next clock cycle until this signal is deasserted, 0=otherwise
| Data Transfer
| p_wr_done
| from block-of-data rd/wr module to user logic
| 1
| 1=this is the last write and no more write will be accepted for this block-of-data, 0=otherwise
|
写DRAM时序如图3.4-7:
图3.4-7 写DRAM时序图
读端口:
Signal Group
| Signal Name
| Direction
| Bits
| Description
| Request Negotiation
| p_rd_req
| from user logic to block-of-data rd/wr module
| 1
| 1=request for read transfer (data are from DRAM to user logic), 0=otherwise
| Request Negotiation
| p_rd_ptr
| from user logic to block-of-data rd/wr module
| PKT_MEM_PTR_WIDTH
| the start address of DRAM for transfer. Each unit is 16-byte piece
| Request Negotiation
| p_rd_ack
| from block-of-data rd/wr module to user logic
| 1
| 1=the arbiter acknowledges that the read requester can proceed, 0=otherwise
| Data Transfer
| p_rd_rdy
| from block-of-data rd/wr module to user logic
| 1
| 1=block-of-data rd/wr module has data for user logic to read, 0=otherwise
| Data Transfer
| p_rd_en
| from user logic to block-of-data rd/wr module
| 1
| 1=user logic reads out one word of data from the block-of-data rd/wr module, 0=otherwise
| Data Transfer
| p_rd_data
| from block-of-data rd/wr module to user logic
| PKT_DATA_WIDTH
| data transferred from block-of-data rd/wr module to user logic
| Data Transfer
| p_rd_done
| from block-of-data rd/wr module to user logic
| 1
| 1=this is the last read data and no more data will be read for this block-of-data, 0=otherwise
|
读DRAM时序如图3.4-8:
图3.4-8 写DRAM时序图
② 其他模块对DRAM控制器的读/写过程:
当DRAM读写控制器将一个数据包读/写完之后, 就将rd_idle/wr_rdy_arb置为1,当外部模块需要对DRAM进行读写时,首先要判断这两个信号是否有效,在有效的情况下进行对数据的操作。.端口列表如下:
信号名称
| 位宽bits
| I/O
| 描述
| wr_vld_arb
| 1
| I
| Input_arbiter输入有效
| out_data_0
| 64
| I
| 输入的数据包的data_bus
| out_ctrl_0
| 8
| I
| 输入数据包的ctrl_bus
| port_num_dram
| 2
| I
| 输入信号的端口号,指明数据存放在DRAM的区域
| wr_rdy_arb
| 1
| O
| 写空闲信号
| port_num_rd
| 2
| I
| 读取数据包的区域
| addr_vld
| 1
| I
| 读地址有效
| block_num_rd
| 8
| I
| 数据包存放的block的起始地址
| rd_idle
| 1
| O
| 读空闲信号
| in_rdy
| 1
| I
| 数据输出输出允许信号
| out_data
| 64
| O
| 读出的数据包的data_bus
| out_ctrl
| 8
| O
| 输出数据包的ctrl_bus
| data_vld
| 1
| O
| 输出数据有效
|
(1)当decode_control_panel对DRAM控制器进行读操作时,将信道号和block地址发送至DRAM控制器,接着DRAM控制器从DRAM中读取数据,当decoder空闲时将数据发送出去,时序图如3.4-9所示:
图3.4-9 对DRAM控制器的读操作
(2)当DRAM控制器进行写操作时,将按照input_arbiter发送过来的端口号,按照地址大小顺序写DRAM,时序图如3.4-10:
图3.4-10 对DRAM控制器的写操作
5、decode_control_panel
① 本模块的内部结构图如3.4-11所示,它由以下五个模块组成:cam_info_save, decode_control_sm和3个CAM组成。
图3.4-11:decode_control_panel内部结构图
本模块的输入输出端口定义表如下:
端口名称
| 位宽 bits
| I/O
| 描述
| port_num_cam
| 2
| In
| 数据写入的CAM号,即信道号
| Src_gen_seq
| 24
| In
| 输入数据包的信源号、代编号
| Cam_vld
| 1
| In
| 写有效
| Cam_rdy
| 1
| Out
| 写Cam准备好
| rd_idle
| 1
| In
| DRAM准备好
| block_num_rd
| 8
| Out
| 读DRAM的地址
| addr_vld
| 1
| Out
| 读地址有效
| port_num_rd
| 2
| out
| 要读取的DRAM的编号
| Pkt_vld
| 1
| Out
| 要解码的数据包输出有效标志
| Pkt_decoding
| 12
| out
| 正在解码的数据包的信源号、代编号
| Decod_com
| 1
| In
| 数据包解码完成标志
| has_other_factor
| 1
| Out
| 有另外一个解码因子
| Pkt_not_find
| 1
| Out
| 所需要解码数据包未找到
| pkt_need_src_gen
| 12
| In
| 解码需要的数据包
| need_pkt_vld
| 1
| In
| 所需数据包有效
| rd_dcod_reg_req_1
| 1
| Out
| 读解码标志寄存器请求
| req_ack_vld_1
| 1
| In
| 标志位有效
| Alredy_Decod_1
| 1
| In
| 解码标志位
| rd_dcod_src_gen_1
| 12
| out
| 查询数据包是否已经解码
|
② cam_info_save:
该模块的主要功能是将输入的数据包的信源号和代的编号按地址大小顺序存入到三个cam中,每个cam分别对应于三个数据输入通道。每个CAM的大小是24bits×256,我们要求CAM的读写操作可以同时进行,写数据从DIN进入,而读(查询)的数据从CMP_DIN进入,写操作时BUSY信号有效,表示不可以响应其他写请求,图3.4-12是一个CAM的读写操作时序:
图3.4-12:CAM读写过程
③decode_control_sm
该模块的功能是按照轮询策略,控制decoder解码储存在DRAM中的数据包。通过查询CAM中的数据包的存储地址,将查询到的地址输出给DRAM读写控制模块,从而找到解码所需要的数据,同时将要查询的数据包的信源号和代的编号发送给解码模块。若不能查找到解码因子,则将信号Pkt_not_find置为有效电平,通知decoder无法解码,同时将状态转到解码下一个数据包的状态上。在开始查找CAM时,要等待储存一定数量的数据包,在我们的系统里面,暂定为32。
状态机处理控制流程如图3.4-13:
图3.4-13:decode_control_sm状态机及数据处理流程
6、decoder
decoder是整个解码路由器的核心之一,它的主要功能是接收来自DRAM的编码后的IP数据包,在decode_control_panel模块的控制下对数据包进行解码,它包括多个小模块,其整体图和内部结构图如3.4-14和3.4-15所示:
图3.4-14 decoder整体结构图
图3.4-15:decoder内部结构图
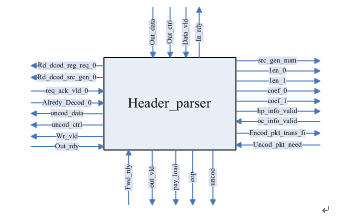
① header_parser
分析接收到的数据包,如果已经被编码,根据包头提取信源号、代号、长度和系数给运算控制模块,如果没有被编码,则查询解码标志寄存器,如果已经解码并储存在二级缓存中,则该数据包只是一个解码因子,把数据发送到fwd_sel,若没有解码,则同时发送到capsulation和forward sel。如果数据是编码后的数据包,则将数据包去掉包头后将数据发送给forward sel模块。当发送到最后的64位数据时,eop信号有效,指明是数据包的最后有效字节。
下图所示为输入输出接口图3.4-16:
图3.4-16:header_parser模块图
其输入输出端口列表如下:
信号名称
| 位宽bits
| I/O
| 描述
| in_rdy
| 1
| O
| 数据输出输入允许信号
| out_data
| 64
| I
| 输入的数据包的data_bus
| out_ctrl
| 8
| I
| 输入数据包的ctrl_bus
| data_vld
| 1
| I
| 输入数据有效
| rd_dcod_reg_req_0
| 1
| O
| 读取解码标志位请求
| rd_dcod_src_gen_0
| 12
| O
| 要读取的数据包的信源号和代编号
| req_ack_vld_0
| 1
| I
| 输入有效
| alredy_decod_0
| 1
| I
| 解码标志(“1”代表已经解码,“0”代表未解码)
| Uncod_data
| 64
| O
| 未编码数据包的数据总线
| Uncod_ctrl
| 8
| O
| 未编码数据包的控制总线
| Wr_vld
| 1
| O
| 写capsulation数据有效
| Out_rdy
| 1
| I
| 输出capsulation允许信号
| fwd_rdy
| 1
| I
| 输出fwd_sel允许信号
| out_vld
| 1
| O
| 输出fwd_sel有效
| pay_load
| 64
| O
| 输出fwd_sel数据(不含包头)
| eop
| 4
| O
| 最后指示一个有效字节的指示
| uncod
| 1
| O
| 指明输出的数据包是否编码
| src_gen_num
| 12
| O
| Decoder接收到的数据包的信源号和代的编号
| len_0
| 16
| O
| 被编码的第一个数据包的有效载荷的长度
| len_1
| 16
| O
| 被编码的第二个数据包的有效载荷的长度
| coef_0
| 8
| O
| 被编码的第一个数据包的编码系数
| coef_1
| 8
| O
| 被编码的第二个数据包的编码系数
| hp_info_vld
| 1
| O
| 输出信息有效
| encod_pkt_trans_fi
| 1
| O
| 编码数据包传输完毕标志
| oc_info_vld
| 1
| I
| 解码控制输入信息有效
| uncod_pkt_need
| 1
| I
| 未编码的数据包是/否解码因子(1=是,0=否)
|
<div style="clear:both;"> ③ RAM读写控制器
在写数据时,先从运算控制模块中得出要储存的RAM号,接着RAM读写控制器将从收到forward sel 模块收到的数据存到片内RAM里面去。在读数据时,根据dcod_operation模块提供的ram号,从相应的ram中读取数据,由于使用的是双端口ram,因此读写可以同时进行。模块信号列表如下:
信号名称
| 位宽bits
| I/O
| 信号描述
| wr_req
| 1
| I
| 写RAM请求
| encod_data
| 72
| I
| 写RAM的数据总线
| ram_data_vld
| 1
| I
| 数据有效
| encod_data_eop
| 4
| I
| 数据包结束标志,指明最后一个有效字节
| wr_ack
| 1
| O
| 写RAM响应
| wr_ram_num
| 2
| I
| 要写入的RAM号
| info_vld
| 1
| I
| 数据有效标志
| req_ram_num
| 1
| O
| 读RAM号请求
| rd_ram_num
| 2
| I
| 需要读取数据的RAM号
| rd_req
| 1
| I
| 读RAM请求
| ram_data_eop
| 4
| O
| 数据包结束标志,指明最后一个有效字节
| ram_data
| 72
| O
| 读RAM的数据总线
| ram_vld
| 1
| O
| 读RAM数据有效
|
RAM读写时序图如图3.4-18:
图3.4-18:RAM读写时序
每个RAM由双端口block RAM组成,位宽为72位,深度为180,因此读写的地址位宽均为8位。由于RAM的读写控制时序是固定的,所以在此不再赘述。
④ operation_control
运算控制(operation_control)是decoder模块的控制核心,它和decode_control_panel配合,完成对编码数据包的解码。
输入输出信号列表:
信号名称
| 位宽bits
| I/O
| 信号描述
| Pkt_vld
| 1
| I
| 要解码的数据包输出有效标志
| Pkt_decoding
| 12
| I
| 正在解码的数据包的信源号、代编号
| Decod_com
| 1
| O
| 数据包解码完成标志
| has_other_factor
| 1
| I
| 有另外一个解码因子
| Pkt_not_find
| 1
| I
| 所需要解码数据包未找到
| pkt_need_src_gen
| 12
| O
| 解码需要的数据包
| need_pkt_vld
| 1
| O
| 所需数据包有效
| src_gen_num
| 12
| I
| Decoder接收到的数据包的信源号和代的编号
| len_0
| 16
| I
| 被编码的第一个数据包的有效载荷的长度
| len_1
| 16
| I
| 被编码的第二个数据包的有效载荷的长度
| coef_0
| 8
| I
| 被编码的第一个数据包的编码系数
| coef_1
| 8
| I
| 被编码的第二个数据包的编码系数
| hp_info_vld
| 1
| I
| 输入信息有效
| encod_pkt_trans_fi
| 1
| I
| 编码数据包传输完毕标志
| oc_info_vld
| 1
| O
| 解码控制输出信息有效
| uncod_pkt_need
| 1
| O
| 未编码的数据包是/否解码因子(1=是,0=否)
| wr_ram_num
| 2
| O
| 要写入的RAM号
| info_vld
| 1
| O
| 数据有效标志
| req_ram_num
| 1
| I
| 读RAM号请求
| rd_info_req
| 1
| I
| 读取解码信息请求
| dcod_info_vld
| 1
| O
| 解码信息有效
| ram_num
| 2
| O
| 解码数据包的所存储的RAM号
| coef_mut
| 8
| O
| 乘法系数
| coef_div
| 8
| O
| 除法系数
| cap_info_req
| 1
| I
| 封装信息请求
| dcod_comp
| 1
| I
| 解码封装完成
| cap_info_vld
| 1
| O
| 封装信息有效
| need_feed_back
| 1
| O
| 需要反馈
| pkt_len
| 16
| O
| 数据包长度
| src_num
| 4
| O
| 数据包的信源号
| gen_num
| 8
| O
| 数据报的代编号
|
Operation_control模块的主要功能是:接收header_parser发送过来的数据,通过计算和比较后与decode control panel通信,告诉decode control panel解码所需要的数据包和解码完成标志;给RAM读写给出RAM号(即存储在哪个RAM中);给decode operation模块提供解码所需要的系数和RAM号;给capsulation模块提供源IP和是否需要反馈数据的命令,其控制状态如图3.4-19下:
图3.4-19:Operation_control状态机处理流程
⑤ decode operation
decode operation是解码运算模块,它将来自fwd_sel模块的未编码的数据和来自RAM的编码数据完成减法和除法运算,还原被编码的数据。解码后将数据总线的位宽恢复为64bits。解码运算模块的端口列表如下:
信号名称
| 位宽bits
| I/O
| 信号描述
| dcod_payload
| 64
| O
| 解码后的数据包的有效载荷
| end_payload
| 4
| O
| 数据包结束标志,指明最后一个有效字节
| payload_vld
| 1
| O
| 输出数据有效
| wr_rdy
| 1
| I
| 输出数据允许信号
| uncod_data_vld
| 1
| I
| 输入至dcod_operation的数据有效
| uncod_data_factor
| 64
| I
| 输入至dcod_operation的数据总线
| uncod_data_eop
| 4
| I
| 数据包结束标志,指明最后一个有效字节
| dcod_rdy
| 1
| O
| 输入至dcod_operation允许信号
| rd_ram_num
| 2
| O
| 需要读取数据的RAM号
| rd_req
| 1
| O
| 读RAM请求
| ram_data_eop
| 4
| I
| 数据包结束标志,指明最后一个有效字节
| ram_data
| 72
| I
| 读RAM的数据总线
| ram_vld
| 1
| I
| 读RAM数据有效
| rd_info_req
| 1
| O
| 读取解码信息请求
| dcod_info_vld
| 1
| I
| 解码信息有效
| ram_num
| 2
| I
| 解码数据包的所存储的RAM号
| coef_mut
| 8
| I
| 乘法系数
| coef_div
| 8
| I
| 除法系数
|
为了快速完成解码运算,我们在此采取并行除法的方法使之能快速解码,解码运算的算法图如图3.4-20:
图3.4-20 decoder_operation内部的并行除法
⑥ capsulation
Capsulation是解码运算的最后一个模块,其主要功能是封装解码后的数据包。其主要任务是:(1)接收来自decode operation和header_parser的数据;(2)将来自header_parser的未编码的数据包去掉NCP包头;(3)计算新的包头校验和,更新TTL;(4)置位解码标志寄存器;(5)将来自decode operation模块的数据,先向运算控制模块询问是否要反馈,若需要,则将数据反馈至forward_sel模块;(6)恢复IP数据包头;(7)将IP包头和有效载荷封装好,并恢复ctrl_bus和module header,将其一起同步发送出去。
端口信号列表如下:
信号名称
| 位宽bits
| I/O
| 信号描述
| decoder_in_rdy
| 1
| I
| 输出至SRAM允许信号
| decoder_in_wr
| 1
| O
| 输出有效
| decoder_in_data
| 64
| O
| 输出至SRAM数据总线
| decoder_in_ctrl
| 8
| O
| 输出至SRAM控制总线
| set_req
| 1
| O
| 置位请求
| set_src_gen
| 12
| O
| 需要置位的数据包(表示已经解码完毕)
| set_info_vld
| 1
| O
| 置位信息有效
| set_ack
| 1
| I
| 置位请求响应
| cap_info_req
| 1
| O
| 封装信息请求
| dcod_comp
| 1
| O
| 解码封装完成
| cap_info_vld
| 1
| I
| 封装信息有效
| need_feed_back
| 1
| I
| 需要反馈
| pkt_len
| 16
| I
| 数据包长度
| src_num
| 4
| I
| 数据包的信源号
| gen_num
| 8
| I
| 数据报的代编号
| dcod_payload
| 64
| I
| 解码后的数据包的有效载荷
| end_payload
| 4
| I
| 数据包结束标志,指明最后一个有效字节
| payload_vld
| 1
| I
| 输入数据有效
| wr_rdy
| 1
| O
| 输入数据允许信号
| fd_back_ack
| 1
| I
| 接受反馈响应
| fd_back_vld
| 1
| O
| 反馈数据有效标志
| fd_back_req
| 1
| O
| 反馈请求
| fd_back_data
| 64
| O
| 反馈数据总线
| fd_back_data_eop
| 4
| O
| 反馈数据结束标志,指明最后一个有效字节
| Uncod_data
| 64
| I
| 未编码数据包的数据总线
| Uncod_ctrl
| 8
| I
| 未编码数据包的控制总线
| Wr_vld
| 1
| I
| 写capsulation数据有效
| Out_rdy
| 1
| O
| 输入数据包允许信号
|
封装过程中的状态转换图如图3.4-21:
图3.4-21capsulation封装包头流程图
7、SRAM读写控制器
SRAM读写控制的作用是:①将capsulation模块来的数据写入SRAM中,写入时按照代的大小和信源号写入block中。SRAM按照地址分为3个区域,每个区域存储对应由一个信源。每个区域分为256个block,每个block深度是400,宽度为36bits,可以存储1800字节的数据(即至少可容纳一个正常大小的IP数据包)。②读取数据时按照block逐个读取,读取后的数据直接发送至output_arbiter。在每发送完一个数据包后,对解码标志寄存器复位。
SRAM读写控制器的端口列表如下:
信号名称
| 位宽bits
| I/O
| 信号描述
| decoder_in_rdy
| 1
| O
| 写SRAM控制器允许信号
| decoder_in_wr
| 1
| I
| 输入有效
| decoder_in_data
| 64
| I
| 输入至SRAM控制器数据总线
| decoder_in_ctrl
| 8
| I
| 输入至SRAM控制器控制总线
| reset_req
| 1
| O
| 复位请求
| reset_src_gen
| 12
| O
| 需要复位的数据包(表示解码后已发送完毕)
| reset_info_vld
| 1
| O
| 复位信息有效
| reset_ack
| 1
| I
| 复位请求响应
| dcod_data_0
| 64
| O
| 输出的IP数据包的数据总线
| dcod_ctrl_0
| 8
| O
| 输出的IP数据包的控制总线
| wr_vld_0
| 1
| O
| 输出有效
| wr_rdy_0
| 1
| I
| 发送数据允许标志
| sram_addr
| 19
| O
| Sram读/写地址
| sram_we
| 1
| O
| Sram写使能
| sram_bw
| 4
| O
| SRAM写入控制信号
| sram_wr_data
| 36
| O
| SRAM写数据总线
| sram_rd_data
| 36
| I
| SRAM读数据总线
| sram_tri_en
| 1
| O
| SRAM写三态控制
|
SRAM的读写时序如图3.4-22:
图3.4-22 SRAM读写时序
4 结论
网络编码从提出到现在已有十年,在这期间,网络编码的理论研究和工程应用不断发展和成熟,基于网络编码的多信源组播系统是网络编码在硬件方面的实现。它突破了以往网络编码的应用研究只停留在软件和虚拟网络,通过搭建实际的组播通信网络,并应用NetFPGA平台使网络编码在硬件中得以实现。
文档的前面分别介绍了网络编码的基本概念和研究动态、编解码策略和算法以及编码、转发、解码三个系统的详细设计方案,包括系统的软硬接口和软件的基本功能。由于系统中的网络编解码都是由硬件完成,软件的功能主要是控制和测试时使用,因此方案设计以硬件为主。
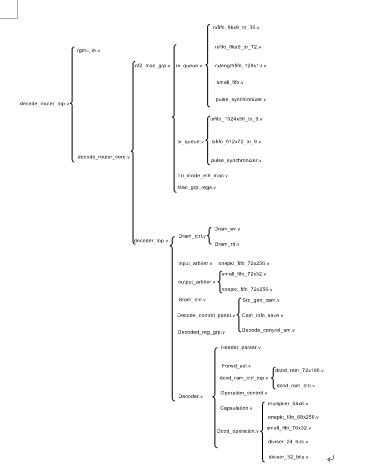
图4-1,图4-2和图4-3分别是编码、转发以及解码路由器三个系统的verilog代码树状图,除去MAC层和core generator产生的代码,代码量有11,000行。附录给出了编码路由器和解码路由器中的关键代码。
图4-1 编码路由器代码树状图
图4-2 转发路由器代码树状图
图4-3 解码路由器代码树状图
附录
附1:编码路由器核心代码:编码模块: payload_router.v
/////////////////////////////////////////////////////////////////////////////
// vim:set shiftwidth=3 softtabstop=3 expandtab:
// Copyright(c) 2009, All rights reserved.
// Advanced Network technology Lab, Shenzhen graduated school of PKU
// Module: payload_router.v
// Project: nf2_coding.ise
// Time and Author: 2009-12-25 liyining
// Description:determine whether should carry out coding operation, and route
// the packets
/////////////////////////////////////////////////////////////////////////////
`define DLY 1
`timescale 1ns/1ns
module payload_router
#(parameter DATAWIDTH = 64,
parameter CTRLWIDTH = DATAWIDTH / 8 //bit-width parameter
)
(
//payload fifo 1 port
input [DATAWIDTH - 1:0] data_payloadfifo_router_1,
input [CTRLWIDTH - 1:0] ctrl_payloadfifo_router_1,
input empty_payloadfifo_router_1,
output reg rd_en_payloadfifo_router_1,
//payload fifo 2 port
input [DATAWIDTH - 1:0] data_payloadfifo_router_2,
input [CTRLWIDTH - 1:0] ctrl_payloadfifo_router_2,
input empty_payloadfifo_router_2,
output reg rd_en_payloadfifo_router_2,
//multiplier 1 port
input rdy_router_multiplier_1,
output reg [DATAWIDTH - 1:0] data_router_multiplier_1,
output reg first_dword_1, //flag to indicate the start of a pkt. only when it is the first double word of a pkt, should the random number be updated.
output reg val_router_multiplier_1,
//multiplier 2 port
input rdy_router_multiplier_2,
output reg [DATAWIDTH - 1:0] data_router_multiplier_2,
output reg first_dword_2, //flag to indicate the start of a pkt. only when it is the first double word of a pkt, should the random number be updated.
output reg val_router_multiplier_2,
//rand number generator port
output reg rand_num_en, //enable the random number generator
input rand_num_val,
//packing fifo port
input rdy_router_packingfifo,
input empty_packingfifo, // only when the whole last pkt is sent out, and the packing fifo is empty, then proceed the next pkt
output reg [DATAWIDTH + CTRLWIDTH:0] data_router_packingfifo, //an extra bit(MSB) to indicate whether it is a coded pkt
output reg val_router_packingfifo,
output reg [2:0] router_status, //send router_status to packing_fifo, indicate where to get data
//misc
input clk,
input rst_n
);
reg [DATAWIDTH - 1:0] data_temp1;
reg [CTRLWIDTH - 1:0] ctrl_temp1;
reg [DATAWIDTH - 1:0] data_temp2;
reg [CTRLWIDTH - 1:0] ctrl_temp2;
reg [1:0] counter_getdata; //counter for the read-FIFO-delay, 1 clock circle
parameter JUDGE = 3'b000;
parameter GET_DATA2 = 3'b001;
parameter SEND_DATA2 = 3'b010;
parameter GET_DATA1 = 3'b011;
parameter SEND_DATA1 = 3'b100;
parameter GET_BOTH = 3'b101;
parameter SEND_BOTH_1 = 3'b110;
parameter SEND_BOTH_2 = 3'b111;
always @(posedge clk or negedge rst_n) begin
//reset process
if (rst_n == 0) begin
router_status <= JUDGE;
data_temp1 <= 64'h0;
ctrl_temp1 <= 8'h0;
data_temp2 <= 64'h0;
ctrl_temp2 <= 8'h0;
counter_getdata <= 2'b0;
end
else begin
case (router_status)
JUDGE: begin
first_dword_1 <= 0;
first_dword_2 <= 0;
rand_num_en <= 0;
val_router_multiplier_2 <= 0; //clear some signals
//program hold, when packing FIFO inempty
if (!empty_packingfifo) begin
router_status <= JUDGE;
end
else begin
//both FIFO ctrl payload 1 & 2 are empty
if (empty_payloadfifo_router_1 && empty_payloadfifo_router_2) begin
rd_en_payloadfifo_router_1 <= 0;
rd_en_payloadfifo_router_2 <= 0;
router_status <= JUDGE;
end
//FIFO ctrl paylaod 2 is inempty, read from this FIFO,
//coding will be unnecessary
else if (empty_payloadfifo_router_1 && (!empty_payloadfifo_router_2)) begin
rd_en_payloadfifo_router_2 <= 1;
rd_en_payloadfifo_router_1 <= 0;
counter_getdata <= 0;
router_status <= GET_DATA2;
end
//FIFO ctrl payload 1 is inempty, read from this FIFO,
//coding will be unnecessary
else if ((!empty_payloadfifo_router_1) && empty_payloadfifo_router_2) begin
rd_en_payloadfifo_router_1 <= 1;
rd_en_payloadfifo_router_2 <= 0;
counter_getdata <= 0;
router_status <= GET_DATA1;
end
//both FIFO ctrl payload 1&2 are inempty, read from both
//of them, coding is needed
else if ((!empty_payloadfifo_router_1) && (!empty_payloadfifo_router_2)) begin
rd_en_payloadfifo_router_1 <= 1;
rd_en_payloadfifo_router_2 <= 1;
counter_getdata <= 0;
router_status <= GET_BOTH;
end
end
end //state JUDGE ends
//read data from FIFO ctrl payload 2
GET_DATA2: begin
val_router_packingfifo <= 0; //clear the output valid signal
//read-FIFO-delay
if (counter_getdata < 2'b01) begin
counter_getdata <= counter_getdata + 1;
router_status <= GET_DATA2;
rd_en_payloadfifo_router_2 <= 0; //clear rd_en signal
end
else begin
data_temp2 <= data_payloadfifo_router_2;
ctrl_temp2 <= ctrl_payloadfifo_router_2;
router_status <= SEND_DATA2;
end
end //state GET_DATA2 ends
//send data to packing fifo without coding
SEND_DATA2: begin
if (!rdy_router_packingfifo) begin
router_status <= SEND_DATA2;
end
else begin
data_router_packingfifo <= {ctrl_temp2, 1'b0 , data_temp2 }; //MSB = 0 means it is an uncoded pkt
val_router_packingfifo <= 1;
//this is the end of a packet, goto JUDGE
if (& (ctrl_temp2)) begin
router_status <= JUDGE;
end
//this is not the end of a packet, goto GET_DATA2
else begin
router_status <= GET_DATA2;
rd_en_payloadfifo_router_2 <= 1;
counter_getdata <= 0;
end
end
end //state SEND_DATA2 ends
GET_DATA1: begin
val_router_packingfifo <= 0; //clear output valid signal
//read-FIFO-delay
if (counter_getdata < 2'b01) begin
counter_getdata <= counter_getdata + 1;
router_status <= GET_DATA1;
rd_en_payloadfifo_router_1 <= 0; //clear rd_en signal
end
else begin
data_temp1 <= data_payloadfifo_router_1;
ctrl_temp1 <= ctrl_payloadfifo_router_1;
rd_en_payloadfifo_router_1 <= 0;
router_status <= SEND_DATA1;
end
end //state GET_DATA1 ends
SEND_DATA1: begin
if (!rdy_router_packingfifo) begin
router_status <= SEND_DATA1;
end
else begin
data_router_packingfifo <= {ctrl_temp1, 1'b0 , data_temp1 }; //MSB = 0 means it is an uncoded pkt
val_router_packingfifo <= 1;
//this is the end of a packet, goto JUDGE
if (& (ctrl_temp1)) begin
router_status <= JUDGE;
end
//this is not the end of a packet, goto GET_DATA1
else begin
router_status <= GET_DATA1;
rd_en_payloadfifo_router_1 <= 1;
counter_getdata <= 0;
end
end
end //state SEND_DATA1 ends
GET_BOTH: begin
first_dword_2 <= 0; //
val_router_multiplier_2 <= 0; //clear valid signal
//read-FIFO-delay
if (counter_getdata < 2'b01) begin
counter_getdata <= counter_getdata + 1;
router_status <= GET_BOTH;
rd_en_payloadfifo_router_1 <= 0;
rd_en_payloadfifo_router_2 <= 0; //clear rd_en signals
end
else begin
data_temp1 <= data_payloadfifo_router_1;
ctrl_temp1 <= ctrl_payloadfifo_router_1;
data_temp2 <= data_payloadfifo_router_2;
ctrl_temp2 <= ctrl_payloadfifo_router_2;
router_status <= SEND_BOTH_1;
end
end //state GET_BOTH ends
//according to the random number generator, data from both
//input channels should be sent out seperately
SEND_BOTH_1: begin
if (!rdy_router_multiplier_1) begin
val_router_multiplier_1 <= 0;
router_status <= SEND_BOTH_1;
end
else begin
data_router_multiplier_1 <= data_temp1;
val_router_multiplier_1 <= 1;
if (ctrl_temp1 == 8'hff) begin
first_dword_1 <= 1;
rand_num_en <= 1;
end
else begin
first_dword_1 <=0;
rand_num_en <= 0;
end
router_status <= SEND_BOTH_2;
end
end //state SEND_BOTH_1 ends
SEND_BOTH_2: begin
first_dword_1 <= 0;
val_router_multiplier_1 <= 0; //clear valid signal
//confirm the first random number is generated successfully
//before enable to generate the second.
if (ctrl_temp1 == 8'hff) begin
if (!rand_num_val) begin
rand_num_en <= 0;
router_status <= SEND_BOTH_2;
end
end
else begin
if (!rdy_router_multiplier_2) begin
val_router_multiplier_2 <= 0;
router_status <= SEND_BOTH_2;
end
else begin
data_router_multiplier_2 <= data_temp2;
val_router_multiplier_2 <= 1;
if (ctrl_temp2 == 8'hff) begin
first_dword_2 <= 1;
rand_num_en <= 1;
end
else begin
first_dword_2 <= 0;
rand_num_en <= 0;
end
if (((ctrl_temp1 == 8'hf0) && (& (ctrl_temp2))) || ((ctrl_temp2 == 8'hf0) && (& (ctrl_temp1)))) begin
router_status <= JUDGE;
end
else begin
rd_en_payloadfifo_router_1 <= 1;
rd_en_payloadfifo_router_2 <= 1;
counter_getdata <= 0;
router_status <= GET_BOTH;
end
end
end
end //state SEND_BOTH_2 ends
endcase
end
end
endmodule
附2:解码路由器核心代码之一:解码控制模块:decode_control_sm. v
///////////////////////////////////////////////////////////////////////////////
// vim:set shiftwidth=3 softtabstop=3 expandtab:
// Copyright(c) 2009, All rights reserved.
// Advanced Network technology Lab, Shenzhen graduated school of PKU
// Module: decode_control_sm.v
// Project: NF2.1
// Time and Author: 2009-12-15 zhang ming long
// Description: According to the pkts' source and generation sequence number,
// this module goes round-robin strategy to control the module decoder
// to decode the pkts stored in DRAMS.
///////////////////////////////////////////////////////////////////////////////
`define DLY #1
`timescale 1ns/1ps
module decode_control_sm
#(parameter SRC_WIDTH = 4,
parameter GEN_WIDTH = 8,
parameter REG_GRP_WIDTH = 12,
parameter SRC_GEN_SEQ_WIDTH = 24,
parameter DRAM_NUMS = 3,
parameter CAM_NUMS = 3,
parameter DRAM_NUMS_WIDTH = log2(DRAM_NUMS),
parameter CAM_NUMS_WIDTH = log2(CAM_NUMS),
parameter DRAM_BLOCK_WIDTH = 8,
parameter CAM_ADDR_WIDTH = 8,
parameter CMP_DATA_MASK = 12'hfff
)
(// --- cam interface
output [SRC_GEN_SEQ_WIDTH-1:0] cmp_data_0,
output reg [SRC_GEN_SEQ_WIDTH-1:0] cmp_data_mask_0,
input [CAM_ADDR_WIDTH-1:0] match_addr_0,
input match_0,
output [SRC_GEN_SEQ_WIDTH-1:0] cmp_data_1,
output reg [SRC_GEN_SEQ_WIDTH-1:0] cmp_data_mask_1,
input [CAM_ADDR_WIDTH-1:0] match_addr_1,
input match_1,
output [SRC_GEN_SEQ_WIDTH-1:0] cmp_data_2,
output reg [SRC_GEN_SEQ_WIDTH-1:0] cmp_data_mask_2,
input [CAM_ADDR_WIDTH-1:0] match_addr_2,
input match_2,
// ---DRAM control interface
output reg [DRAM_NUMS_WIDTH-1:0] port_num_rd,
output reg [DRAM_BLOCK_WIDTH-1:0] block_num_rd,
output reg addr_vld,
input rd_idle,
// ---input_arbiter interface
input cam_vld,
// ---decoder interface
output reg pkt_vld,
output reg [REG_GRP_WIDTH-1:0] pkt_dcoding,
output reg pkt_not_find,
output reg has_other_factor,
input [REG_GRP_WIDTH-1:0] pkt_need_src_gen,
input need_pkt_vld,
input decod_com,
// ---decoded reg grp interface
output reg rd_dcod_reg_req_1,
output [REG_GRP_WIDTH-1:0] rd_dcod_src_gen_1,
input req_ack_vld_1,
input alredy_decod_1,
// --- Misc
input rst_n,
input clk
);
function integer log2;
input integer number;
begin
log2=0;
while(2**log2<number) begin
log2=log2+1;
end
end
endfunction // log2
// ------------ Internal Params --------
parameter NUM_STATES = 4;
parameter IDLE = 4'b0;
parameter GET_SRC_GEN_NUM = 4'b0001;
parameter LOOK_UP_CAM = 4'b0010;
parameter GET_CMP_RESLT_FIRST = 4'b0011;
parameter GET_CMP_RESLT_SEC = 4'b0100;
parameter RD_DRAM_MAIN_STEP = 4'b0101;
parameter LUP_DCOD_FACTOR1_FIRST = 4'b0110;
parameter LUP_DCOD_FACTOR1_SEC = 4'b0111;
parameter GET_FACTOR1_RESLT = 4'b1000;
parameter RD_DRAM_MINOR_STEP = 4'b1001;
parameter LUP_DCOD_FACTOR2 = 4'b1011;
// ------------- Regs/ wires -----------
wire [SRC_WIDTH-1:0] src_num_plus1;
reg [SRC_WIDTH-1:0] src_num,src_num_sel,src_num_sel_next; //source sequence number for packets that is being decoded
reg [SRC_WIDTH-1:0] src_num_next;
wire [GEN_WIDTH-1:0] gen_num_plus1;
reg [GEN_WIDTH-1:0] gen_num,gen_num_sel,gen_num_sel_next; //generation sequence number for packets that is being decoded
reg [GEN_WIDTH-1:0] gen_num_next;
reg [CAM_NUMS-1:0] cam_lookup_reslt; // result of looking up packets in cam,stands for which cam finds the packet
reg [CAM_NUMS-1:0] cam_lookup_reslt_next;
reg[CAM_NUMS-1:0] cam_lookup_reslt_pre,cam_lookup_reslt_save;
reg[CAM_NUMS-1:0] cam_lookup_reslt_pre_next,cam_lookup_reslt_save_next;
reg [CAM_ADDR_WIDTH-1:0] other_dram_addr;
reg [CAM_ADDR_WIDTH-1:0] other_dram_addr_next;
reg [DRAM_NUMS_WIDTH-1:0] other_port_num_rd; //the other result from looking up cams
reg has_factor2; //has the other looking up result
reg has_factor2_next;
reg [DRAM_NUMS_WIDTH-1:0] other_port_num_rd_next;
reg [NUM_STATES-1:0] state;
reg [NUM_STATES-1:0] state_next;
reg [4:0] couter;
wire [4:0] couter_next;
reg couter_start;
reg[CAM_ADDR_WIDTH-1:0] atch_addr_temp_2,match_addr_temp_2_next;
reg[CAM_ADDR_WIDTH-1:0] match_addr_temp_1,match_addr_temp_1_next;
reg[CAM_ADDR_WIDTH-1:0] match_addr_temp_0,match_addr_temp_0_next;
reg [SRC_GEN_SEQ_WIDTH-1:0] cmp_data;
// ------------ main code and logic -------------
assign src_num_plus1 = (src_num == 2) ? 0 : src_num + 1;
assign gen_num_plus1 = (gen_num == 2**GEN_WIDTH-1) ? 0 : gen_num + 1;
assign rd_dcod_src_gen_1 = {src_num_sel,gen_num_sel};
assign couter_next = (couter_start == 1) ? couter+1 : couter;
assign cmp_data_0 = cmp_data;
assign cmp_data_1 = cmp_data;
assign cmp_data_2 = cmp_data;
/* This state machine completes decode control task. If enough packets have
* been saved in cams and DRAMS, it starts to decode to packets. If
* a packet can not be decoded becouse of losing, it will decode the next
* packet automatically */
always @(*) begin
state_next = state;
gen_num_next = gen_num;
src_num_next = src_num;
src_num_sel_next = src_num_sel;
gen_num_sel_next = gen_num_sel;
cam_lookup_reslt_next = cam_lookup_reslt;
rd_dcod_reg_req_1 = 1'b0;
addr_vld = 1'b0;
pkt_vld = 1'b0;
pkt_not_find = 1'b0;
other_dram_addr_next = other_dram_addr;
other_port_num_rd_next =other_port_num_rd;
has_factor2_next = has_factor2;
pkt_dcoding = 12'hfff;
block_num_rd = 2'b0;
cam_lookup_reslt_pre_next = cam_lookup_reslt_pre;
cam_lookup_reslt_save_next = cam_lookup_reslt_save;
port_num_rd = 2'b11;
couter_start = 1'b0;
match_addr_temp_2_next = match_addr_temp_2;
match_addr_temp_1_next = match_addr_temp_1;
match_addr_temp_0_next = match_addr_temp_0;
cmp_data_mask_0 = 24'h0;
cmp_data_mask_1 = 24'h0;
cmp_data_mask_2 = 24'h0;
has_other_factor = 0;
cmp_data = 24'hffffff;
case(state)
/* --- waiting for the cam has been writen enough packet */
IDLE: begin
if(cam_vld) begin
couter_start = 1;
end
if(couter == 5'b11111)
state_next = GET_SRC_GEN_NUM;
end
/* Goes round-robin around the sources and generations,
* gets the source sequence number and generation sequebce
* number of a packet need to be decoded */
GET_SRC_GEN_NUM: begin
state_next = LOOK_UP_CAM;
rd_dcod_reg_req_1 = 1; // read the decoded reg grp
src_num_sel_next = src_num;
gen_num_sel_next = gen_num;
src_num_next = src_num_plus1;
if(src_num == 4'b0010)
gen_num_next = gen_num_plus1;
end
/* --- look up pkt in three cams to get block number of DRAM*/
LOOK_UP_CAM:
if(req_ack_vld_1) begin
if(alredy_decod_1 == 1) // it has been decoded,decode the next packet
state_next = GET_SRC_GEN_NUM;
else begin
cmp_data = {src_num_sel,gen_num_sel,12'hfff};
cmp_data_mask_0 = {12'h0,CMP_DATA_MASK};
cmp_data_mask_1 = {12'h0,CMP_DATA_MASK};
cmp_data_mask_2 = {12'h0,CMP_DATA_MASK};
state_next = GET_CMP_RESLT_FIRST;
end
<p> &nb |






 雷达卡
雷达卡
 发表于 2015-4-26 17:36:24
发表于 2015-4-26 17:36:24








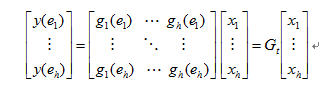






































 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 微信
微信 收藏
收藏 分享
分享 支持
支持 反对
反对 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 抢沙发
抢沙发 千斤顶
千斤顶 显身卡
显身卡