|
|
一 研究的目的和意义
计算机智能化一直是计算机科学人员研究的重点和计算机发展的方向,计算机智能化首先离不开的就是人机交互,早期计算机通过键、鼠标、扫描仪等等就像与计算机的交互作业,
但是随着人们对计算机的功能和需求日益增长,这些最基本的交互工具已经不能满足人们的要求了,人们希望计算机能像一个人一样跟自然人进行交流,希望能够有更好的交互设备的出现。 人类的感知能力很强,可以通过声音、图像、触觉等等来认识这个世界,同样我们也希望计算机能做到这一点,语音识别无疑是在这方面领域的一大突破。
语音识别技术是集声学、语音学、语言学、计算机、信息处理和人工智能等诸领域的一项综合技术。其根本目的在于让人机交互更方便、自然、易用。为了对语音识别技术的了解和研究。我们应用xilinx公司的fpga平台软件和XUPV2Pro开发板,运用语音来控制选频滤波器的的滤波范围。选择xilinx的XUPV2Pro开发板主要是因为XUPV2Pro开发板中包括了LM4550音频编解码芯片,可以实现语音信号的采集、编码。 另外此开发板的核心芯片Virtex2 Pro包含了1万3千多个Slice,嵌入了PowerPC和MircoBlaze,功能强大,可以实现各种逻辑运算和算术运算,在本设计中用它实现了语音识别和选频滤波器的功能。
二 研究主要内容和结构安排
目前许多语音识别的算法研究都是基于软件平台的,真正的语音识别硬件实现很少,我们的研究针对小词汇量孤立词非特定人的语音识别系统,学习并研究当前主流的语音识别算法。
主要内容:
(1)研究并使用多种fpga设计方法对数字信号处理:硬件DSP的Matlab建模设计方法;IP核设计方法等等。运用这些算法实现 FFT 、DCT、和乘法、对数运算,在fpga中综合运用这些方法。
(2)首先语音识别的第一步就是从XUPV2Pro开发板上的ac97芯片中得到语音的数字信号,即从ac97中提取出声音信号,以待处理。
(3)语音识别的前端处理(预处理和端点检测),这部分算法直接由同学根据其软件算法用hdl语言编程实现成硬件模块,留出端口。
(4)在前端处理后,下面的工作就是对语音信号进行特征提取的工作。在比较各种语音特征参数的优缺点之后,我们选定MFCC参数作为非特定人的语音特征。采用矢量量化来进行编码压缩来节约存储空间。此项处理我们也采用硬件结构来实现。
(5)对于语音识别过程中的训练与匹配问题,我们采用隐马尔可夫模型。对于隐马尔可夫同样用硬件描述语言编写代码实现该算法。
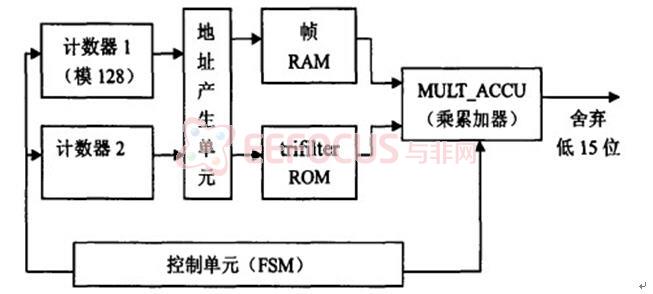
三 基本结构图
四 模块具体实现介绍
1、语音信号的提取
语音识别的第一步就是要将话筒传来的信号转成计算机能处理的数字信号,实现模拟信号向数字信号的转换。XUPV2Pro开发板自带lm4550 ac‘97芯片,我们可以通过ac97芯片来获得所需要的数字信号。
2、前端处理部分(预处理和端点检测部分)
前端处理包括预加重、分帧、加窗、以及本设计基于状态机的端点检测,是语音识别的前端处理,我们采用传统的hdl语言设计模块的方法。
(1) 为了便于实现,FIR预加重滤波器用差分方程表示为:
S=S-0.94*S[i-1] 0≦i≦N
其中,S为原始语音信号序列,N为语音长度,上面显示其在时域上的特性。又因为0.94接近15/16,所以将上面的式子变为
S=S-15/16*S[i-1] =S-(-S[i-1]-S[i-1]/16)
除以16可以用右移4位来实现,这样就将除法运算化简为移位运算,降低了计算的复杂度。在后面的模块设计中,也称以或者除以一些这样的数,这些数为2的幂次,都可以用移位来实现。
预加重的硬件实现图如下:
(2)分帧的DSP Builder实现:
语音信号在10到20ms之间保持短时平稳,也就是说选取的帧的长必须介于10到20ms之间,此外,在MFCC特征提取时要进行FFT变换,FFT点数一般为2的幂次所以我们选择帧的长度为16ms,帧移为1/2帧长,这样一帧包含了16khz×16ms=256点,既满足短时平稳,有满足FFT变换的要求。
为了使帧与帧之间平滑过渡,保持连续语音流的字相关性和过渡性,采用交叠分帧的方法。帧移取1/2帧长,也就是128个数据点当作一个数据块。分帧图如下:
分帧实现框图
FIFO1大小为一帧语音长度,分为两个数据块,预加重后的数据写入这个FIFO。为了实现帧移交叠,在FIFO1读数据时,同时再用FIFO2保存起来,当FIFO1的一块数据读完以后,紧接着从FIFO2读除这一块的副本。写入的一块数据,相当于重复读出2次,所以FIFO1的读时钟频率设计为写时钟频率的2倍,而FIFO2的读写时钟频率和FIFO1的读时钟频率相同。分帧后的数据在途中被以时间标号为1、2、3、3.。。。。。。,1、2为第一帧,2、3为第二帧,以此类推。
FIFO的写信号一直为1,等到写完第一块(128点)在允许读。当FIFO1读第一块数据是,FIFO2保存第一块的数据,两者时钟频率一致,同时FIFO1也在写第2块数据。FIFO1读完第一块数据,FIFO2里为第1块数据,FIFO1中第2块数据写了一半,此时禁止FIFO!读,并使能FIFO2读信号,从FIFO2中将第1块数据再读一遍,读完时第2块数据已经完全写入FIFO1,zai允许FIFO1读,同时禁止FIFO2读,如此循环。途中,数据选择就是为了实现两个FIFO读,同时禁止FIFO2读,如此循环。图中,数据选择器就是为了实现两个FIFO的读出数据选通,第一次数据为FIFO1的读出内容,第2次数据是为了FIFO2读出内容,这样就实现将一块数据内容重复输出两次,读完两次的同时,写完下一块内容。
(3)加窗的DSP Builder实现
分帧后数据为8位定点Q0(即8位有符号整数),三角余玄函数的范围-1到1,可以用Q15来表示,但是Q15能表示的范围为-1到32767/32768之间。加窗的主要对象是查找表,
(4)端点检测
端点检测分门限计算和状态机检测两部分,由于端点检测是基于帧能量的,必须计算每帧的能量,所以增加一个乘累加器和控制时钟,在加窗的同时将每帧能量值计算出来。具体的硬件实现已经上传源代码(verilog语言)。
3.特征提取部分
MFCC特征提取
MFCC特征提取软件算法是将线性功率频谱转化为Mel频率下的功率谱,在计算之前在语音在语音的频谱范围内设置若干个三角带通滤波器,其中心频率fm在Mel频率上是均匀分布的。在线性频率上,当m较小时,相邻的fm间隔很小,随着fm的增加相邻的fm间隔逐渐增大,如图:
各三角滤波器是相互交迭的,每个滤波器三角形两个底点是
相邻滤波器的中心,则
实际频率转换为Mel频率的公式为:
Mel(f)=2595lg(1+f/700) (1)
Mel频率转换为实际频率(Hz)的公式为:
Freq=700*(10 exp(Mel/2595)-1) (2)
本实验采用的三角滤波器组个数L=23,因为L为23时识别率相对最高。再计算23组三角滤波器的下限、中心和上限频率时,根据截止频率,这里为16000/2=8000Hz,先用公式1在Mel频率上计算出均匀分布的23组滤波器的中心频率,再用公式2将Mel中心频率转换成实际中心频率(Hz)。得到23组三角滤波器的中心频率(Hz)和带宽(Hz)如下:
| 序号
| 中心频率
| 带宽
| 序号
| 中心频率
| 带宽
| | 1
| 77
| 86
| 13
| 2401
| 303
| | 2
| 163
| 96
| 14
| 2344
| 337
| | 3
| 259
| 106
| 15
| 2681
| 374
| | 4
| 365
| 118
| 16
| 3055
| 416
| | 5
| 483
| 131
| 17
| 3471
| 462
| | 6
| 614
| 145
| 18
| 3933
| 513
| | 7
| 759
| 162
| 19
| 4446
| 570
| | 8
| 921
| 179
| 20
| 5016
| 633
| | 9
| 1100
| 200
| 21
| 5649
| 703
| | 10
| 1300
| 221
| 22
| 6352
| 780
| | 11
| 1521
| 246
| 23
| 7132
| 868
| | 12
| 1767
| 274
|
|
|
|
求取MFcc参数的大致过程如下:
(l)预加重Pre一emphasis,加强语音中的高频部分。
(2)加窗Windowing,使语音平滑过渡,保持自相关性。
(3)对加汉明窗后的语音帧作快速傅立叶变换 (FastFourierTransformation,FFT),将时域信号转化为频域 (FrequencyDomain)信号。
(4)从FFT输出的数据取模的平方后,得到其离散功率谱,并通过一组三角带通滤波器 (TriangularFihers)。
其中,Xk为功率谱上第k个点的值,mi为第i个滤波器的输出,Ti为第i个滤波器的中心频率。
(5)将三角滤波器组的输出取自然对数,用离散余弦变换 (DisereteCosine升即sformation,DCT)将滤波器输出变换到倒谱域,即可得到MFCC。
其中,P为MFCC参数的阶数。Mk为MFCC参数。
MFCC特征提取的硬件设计流程如图:
由于在端点检测的时候已经进行了预加重和加窗处理,所以直接从FFT部分开始计算,FFT模块的输入除了加窗后的语音还有一帧语音的开始和结束(就是端点检测模块的输出win_data、sop和eop)。因为语音数据都是实数,所以本文在FFT运算上提出了一点改进,可以加速FFT运算速度。FIFO缓冲的读写速度是不一样的。如果前一帧的MFCC参数计算已经完成,并且FIFO中的数据个数大于128(FFT变换后取前面128个值),帧RAM就读128个数据(即一帧)到帧RAM中,并发出信号表示新的一帧计算开始,在该帧没有计算完成之前是不能有新的数据进入帧RAM的。为了加快MFCC参数计算速度,本文将三角滤波器组、对数运算和DCT三个串行的模块,设计成三级流水处理。
本实验中FFT的设计是在ISE10.1软件平台下完成的,在软件平台上,选用V6的板,直接条件FFT的IP核,对I/O数据流结构选项包括:流、缓冲突发和突发(Burst)进行处理,对参数进行设定
dsta_imag_in:输入数据的虚部。
dsta_real_in:输入数据的实部。
Inv_i:为1表示做IF可变换,为O做FFr变换。
master_sink_dsv:置位表示数据源准备好。
master_sink_sop:置位表示输入模块的开始。必须和输入模块的第一个样点同步,并维
持一个时钟周期。
master_source_dav:置位表示设备接受器可以接受输出数据模块。
reset:置位表示同步复位。
exponent_out:表示FFr输出数据的指数。
fft_imag_out:输出数据的虚部。
fft_real_out:输出数据的实部。
master_sink_ena:FFT核函数准备好,可以将输入模块写入其输入缓冲。
master_source:FFT输出数据准备好,可以送到数据接受器。
master_source_eop:输出模块数据包的终点。
master_source_sop:输出模块数据包的起点。
FFTStreaming1/0数据流模块的工作流程:
在系统复位信号(reset)变为低电平后,数据源将 master_sink_dav置为高电平,对FFT函数来说,表明在输入端至少有256个复数据样点可以输入。作为回应,FFT函数将 master_sink_ena信号置高电平,表明其有能力接受这些输入信号。数据源加载第一个数据样点到FFT函数中,同时将master_source_sop置高电平,表示输入模块的开始。在下一个时钟周期, master_sink_sop复位,并以自然顺序加载后面的255个输入数据样点。在Streaming数据流结构中,FFT函数希望输入端口的输入数据连续可用,因此, master—_sink_ena一直保持高电平,除非系统复位,或由于master_sink_dav信号复位显示输入数据模块不完整,master_sink_sop信号置高电平失败,master_sink_ena信号才复位。如果要在一个输入模块的边界上停止模块数据流, master_sink_sop信号在前一个模块的最后数据样点输入以后就将保持低电平。FFT函数会复位master_sink_ena信号,并继续处理已经载入的数据模块。FFT函数中的流水线己经清除以后,master_sink_ena重新置为高电平,通过在下一个输入模块流的第一个输入数据样点上置位mastel_sink_sop信号来初始化下一个输入模块的读取。
当FFT己经完成了输入模块的变换,并且从设备源端将master_source_dav信号置高电平(表示数据从设备接收器可以接收输出数据模块)时,FFT将 master_source_ena信号置高电平,并且以自然顺序输出复数变换域数据模块。FFT函数在master—source_sop信号上输出一个高电平脉冲表示第一个输出样点。128个时钟周期后,master_source-eop信号被置为高电平,表示转换输出数据块结束。
三角滤波器组在前面已经介绍了,其重要计算公式是:
其中,每个三角滤波器的中心频率为T云(见表),这里引入T0和T24方便计算,则T0为0,T1为77,……,T23为7132,T24为8000。采样频率 16KHz,对于256个点的FFT变换,频率分辨率为62.5。用滤波器组的中心频率除以频率分辨率,计算出它对应于FFT频谱中的第几点,T0到T24对应的点为:
| 中心序号
| FFT中对应点
| 中心序号
| FFT中对应点
| | T0
| 1
| T13
| 33
| | T1
| 2
| T14
| 38
| | T2
| 3
| T15
| 43
| | T3
| 5
| T16
| 49
| | T4
| 6
| T17
| 56
| | T5
| 8
| T18
| 63
| | T6
| 10
| T19
| 72
| | T7
| 13
| T20
| 81
| | T8
| 15
| T21
| 91
| | T9
| 18
| T22
| 102
| | T10
| 21
| T23
| 115
| | T11
| 25
| T24
| 128
| | T12
| 29
|
|
|
根据上表,计算出http://www.eefocus.com/fpga/335230/file:///C:UsersADMINI~1AppDataLocalTempmsohtmlclip1\01clip_image013.jpg和http://www.eefocus.com/fpga/335230/file:///C:UsersADMINI~1AppDataLocalTempmsohtmlclip1\01clip_image014.jpg的值建立一张大小为128x23=2944的表,分别对应
FFT频谱中的点。帧RAM中数据为16位正整数。三角滤波器组的值都在0-1之间,为方便计算将滤波器组数值定标为16位Q15,所有数字都扩大2“15=32768倍,并保存在ROM中。则三角滤波器的输出就变成:
其基本结构如下:
取对数
通过三角滤波器后的数值为16位正整数,去底数为10的对数lg(x),可以换成底数为2的对数,这样就变成了log2(x)的值,略有改动的是将两个表放进一个DPROM中,这样可以同时读出两个数,最后结果也不为31位的Q15,因为要乘以常数0.301,所以最后结果为47为Q30,第一位为符号位。
16位正整数最大为32767,而lg在(0,32767]上是单递增的,所以最大数为lg(32767)=4.515,为了保证一定的精度,结果取47中的34到19位,即结果为16为的Q11,1位符号位,5位整数,11位小数,这样的取法有利于接下来的DCT计算。
这一部分的实现是利用Verilog编程语言实现的。
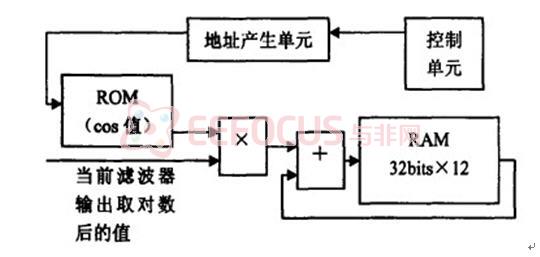
离散余弦变换(DCT)
一维DCT这部分相对比较简单,离散余弦变换 (DiscreteCosineTransform,简称DCT变换)是一种与傅立叶变换紧密相关的数学运算。是数码率压缩需要常用的一个变换编码方法。因为没有现成的IP核,且语音中的优T变换是一维的,所以本文采用硬件描述语言来设计。
在图像处理中,DCT是先将整体图像分成 NXN像素块,然后对 NXN像素块逐一进行DCT变换。由于大多数图像的高频分量较小,相应于图像高频成分的系数经常为零,加上人眼对高频成分的失真不太敏感,所以可用更粗的量化,因此传送变换系数所用的数码率要大大小于传送图像像素所用的数码率。到达接收端后再通过反离散余弦变换回到样值,虽然会有一定的失真,但人眼可以接受。但是对于流水这种结构就不适用了。因为这种方法需要等23组滤波器组的输出结果都取完对数后刁能进行DCT运算,所以这里做了一些改动,考虑在一个滤波器组输出取对数后就开始进行DCT,修改后增加了一个DPRAM保存临时计算结果,改进后的结构如下:
实现的过程是利用Verilog编程语言实现的。
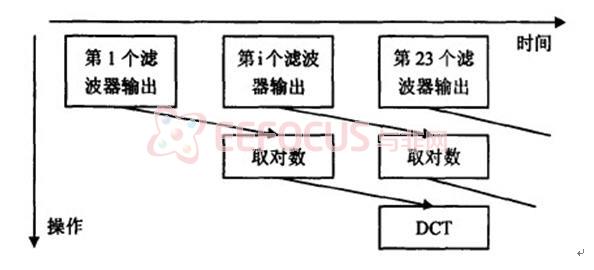
三级流水加速
三角滤波,取对数和离散余弦本来三个操作是串联实现的,现在采用三级流
水结构,使其完成其中一部分时就开始下一个操作,三个操作从一定意义上并联
起来,加快了速度。三级流水示意图如下:
4.训练模式匹配部分
对于训练识别采用HMM模型,viterbi算法,我们采用无跨越的从左至右的HMM模型,状态数为4。这里我们对viterbi算法的原始公式改进,对原始公式中∏、A、B取对数,减小乘法数据下溢问题,此外这样做有利于FPGA实现,可以减少乘法操作消耗的大量时间。由于∏、A、B都是小数,去对数后∏、A、B变成负数,所以考虑去掉符号位进行预算,对于求最大值就变为最小值。下面是对改进的viterbi算法结构介绍。
Viterbi算法改进:
- 初始化 δ[1][1]= ∏[j]+b[j][O(1)], 1≦j≦4
- 递归 δ[t][j]=min[δ[t-1]+a[j]]+b[O(t)], 2≦t≦T 1≦j≦4
φ[j]=argmin[δ[t-1]+a[j]] 2≦t≦T 1≦i j≦4
- 终止 p=δ[T][4] q[t]=4
- 路径回溯,确定最佳状态序列
q[t]= φ[t+1][q[t+1]],t=T-1,T-2,…,1
硬件结构:
分析玩上面的公式,viterbi算法最核心的部分就是第二部分递归:
δ[t][j]=min[δ[t-1]+a[j]]+b[O(t)], 2≦t≦T 1≦j≦4
下面是过程处理单元:
PE(process)单元
PE单元,用到了加比选单元,选择最小的和输出。在此之后,又用了一个数据选择器MUX,是因为第一帧的时候是特殊情况,不需要加比选单元,只要加上初始概率就行。
Viterbi算法的数据来源是∏、A、B,这些数据我们由matlab训练好,可以作为初始化数据保存在RAM中。观察之符号序列O由前面特征提取模块和矢量量化模块的到,作为初始化数据存入cf卡中。
[table] [tr] [td] [table=98%] [tr] [td] 观察值符号序列 |
|






 雷达卡
雷达卡
 发表于 2015-4-27 16:12:36
发表于 2015-4-27 16:12:36





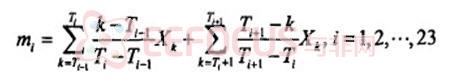
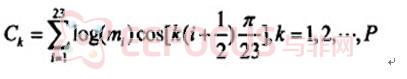


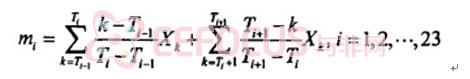
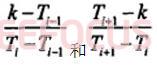

 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 微信
微信 收藏
收藏 分享
分享 支持
支持 反对
反对 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 抢沙发
抢沙发 千斤顶
千斤顶 显身卡
显身卡