|
|
一、应用前景
四、原理和技术特点
4.1 JPEG2000的算法特点
与JPEG相比,JPEG2000算法的显著特点是用DWT取代了DCT,用EBCOT取代了哈夫曼编码(Huffman)。
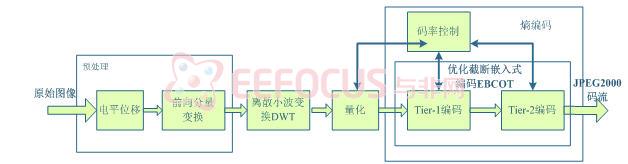
JPEG2000可以分为三个关键步骤:先是小波变换,把图像分解为空间频域子带;然后把每个子带分为较小的块,独立编码成为嵌入式比特流;最后,嵌入式比特流被包装成分层码流。这三部分,简单来说就可以分为DWT、EBCOT第一层编码(Tier-1)和第二层编码(Tier-2)三个模块。再加上预处理阶段,以及量化阶段,组成完整的编码器。
JPEG2000编码器的框图如图4-1所示
图 4-1编码器结构框图
在编码器中,首先对源图像进行前期预处理,对处理的结果进行离散小波变换,得到小波系数。然后对小波系数进行量化和熵编码,最后组成标准的输出码流。具体过程如下:
将有多个颜色分量组成的图像分解成单一颜色分量的图像。分量之间存在一定的相关性,通过分解相关的分量变换,可减少数据之间的冗余度,提高压缩效率;
分量图像被分解成大小统一的矩形片----图像片(Tile)。图像片是进行变换和编解码的基本单元;
对每个图像片进行小波变换。产生多级系数图像。这些不同级数的系数图像可以重构出不同分辨率的图像;
多级分解的结果是由小波系数组成的多个子带。它们表示图像片中局部区域的频率特性;
对系数子带进行量化,并且组成矩形数组的“码块”(Code Block);
对一个码块中的系数位平面(也就是一个码块中整个系数中具有相同权值的那些位)进行熵编码;
将所有码块的压缩位流适当的截取,组织成具有不同质量级的压缩位流层;
将压缩码流以包为单元进行组织,产生JPEG2000文件格式的码流
4.2 组成部分
1、预处理
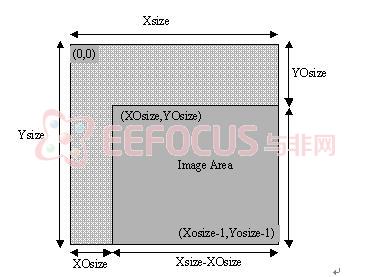
(1)图像分片
图像越大,所占用的内存越大,为此,编码器把图片切分成几个相互独立的矩形切片,对每个切片独立编码。
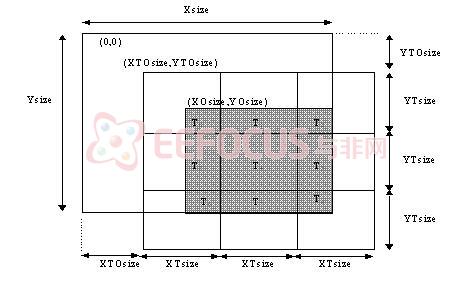
如图2-3所示,这些切片的格子覆盖在参考网格的上面,每个切片长宽分别为XTsiz和YTsiz。这些切片格子的原点是(XTOsiz,YTOsiz)。切片的大小为XTsiz*YTsiz。各切片的标号由光栅扫描顺序来标记。
图4-2 参考网格
图4-3图像切片
(2)DC电平位移
编码器假定输入数据有一个标准的动态范围,并且以0为中心。如果样本是无符号数,每个样本用p位比特表示,就用2p-1去减样本值。目的是在解码时,能够从有符号的数值中正确恢复重构的无符号样本值。直流电平位移是对仅有有符号数组成的图像片的像素进行的。电平位移并不影响图像的质量,在解码端,在离散小波变换之后,对重构的图像进行反向直流电平位移。
(3)分量变换
彩色图片有3个图像分量RGB组成,分量变换把图像从RGB映射到YCrCb上。有两种变换模式:实型的不可逆颜色变化(ICT)和整型的可逆颜色变换(RCT)。
ICT定义为:
U0(x,y)、U1(x,y)、U2(x,y)分别代表红、绿、蓝三种颜色。V0(x,y)、V1(x,y)、V2(x,y)分别代表Y、Cr和Cb三种。
对于ICT来说,RCT就是一个可逆的整数到整数的类似过程:
2、小波变换
通过小波变换,一个分量将分成多个子带。由于这些子带具有统计特性,变换后的数据在编码时一般具有更高的效率。在编码器中,支持可逆的整型小波变换和不可逆的实型小波变换,分别由5/3小波滤波器和9/7小波滤波器实现。完全重构的均匀极大采样的滤波器组(PR-UMDFB)用来实现小波变换。提升算法比传统的卷积方法占用更少的内存、效率更高。一维UMDFB的提升实现如图:
图4-4 滤波器组结构
Ai(z)、Qi(z)和si分别是滤波器函数、量化因子和(标量)增益。
(1)5/3小波一维DWT的实现

(2)9/7小波一维DWT的实现
3、量化
量化的目的是通过把系数限制在一个比较小的精度范围,或者是想要的图像质量。通常,量化器都会采用下式(不同的子带使用不同的量化步长):
其中△就是量化步长,U(x,y)是输入的子带样本,V(x,y)是量化器输出的子带样本。
这里引入了量化死区的概念,即在距离0小于一倍步长的样本值都会量化为0。
4、EBCOT
量化后每个子带的小波系数,在编码之前会分成矩形的编码块。编码块的大小可以任意,但是要满足两个条件:1)编码块的宽和高都必须是2的幂次,2)块大小不能超过4096。一般选择大小为64*64。每个编码块将进行接下来的Tier-1编码,即位平面编码。
Tier1
每个位平面提供3个通道编码,根据重要性,依次是重要性传播通道、幅度细化通道、清除通道。位平面上每个元素因其不同情况,进入不同的通道进行编码。最终每个通道输出编码符号。通道数据再进过基于上下文的算术编码。
重要性传播通道的编码过程:
如果一个样本还没有被发现是重要的,并被预测为有可能是重要的,那么这个样本的重要性就在这个通道中编码成一个二进制标号。如果这个样本的确是重要的,紧接着要对它的符号进行编码,同样编码成一个二进制标号。
幅度细化通道的编码过程:
如果一个样本在之前的重要性传播通道中被发现是重要的,那么该样本的第二位将在这里被编码成一个二进制标号。
清除通道的编码过程:
清除通道按顺序每次处理一个垂直扫描列,直至样本处理完毕。如果垂直扫描的列中有4个样本通过清除通道(即全部样本),我们就要知道4个样本的所有重要性信息,而且如果4个样本都被预测为不重要的话,我们就要进入一个特殊的模式:集合模式(aggregation mode,就是行程编码)。在这个模式里,要记录在垂直列上的最前面几个不重要样本的个数。因此,在这个垂直列上的重要性信息在这个模式上将不被记录,列中剩下的样本将像重要性传播过程那样来编码。
Tier2
在Tier-2中,编码通道的数据将被打包成数据包,这些数据包随后输出成最终的代码流。如果保留所有的编码数据,就是无失真压缩。为了满足一定的压缩比,会截断一些不重要的通道数据,为了达到不同的渐进传输方式,打包的顺序也会不同。
码率的伸展是通过(质量)层来实现。每个切片的编码后数据都被分成L层,那些包含了最重要信息的编码通道数据被放在低层中,而那些包含了更多细节的编码通道数据被放在更高的层中。通过解码,重构出来的图像质量通过每一个层数据的叠加来提升。率控制机制就必须决定哪些层包含哪些通道数据。率控制依靠编码器预先计算出的每个通道对于码率的贡献,和每个通道相关的失真率,选择那些能降低失真的通道,直到数据量达到预先要求。
5、编码流结构和文件结构
为了对图像的编码后数据做一个规范,编码后的数据要组织成一个代码流,包括主文件头、切片文件头、切片主体、主尾部记录这几部分。
一个代码流提供了解码图像时所需要的最基本信息,我们还需要知道图像的其他信息(如版权、产地等)。为了以上的数据能被显示出来,编码器需要一个额外的文件格式。文件结构由不同等级的属性框组合而成。
五、硬件实现
5.3 DWT部分的硬件结构
经过这段时间的调用,阅读文献,决定采用“High-Speed VLSI Implementation of 2-D Discrete Wavelet Transform”,Chao Cheng and Keshab K. Parhi文中描述的算法。该算法具有对称统一的结构,可以方便的均衡硬件使用和分解效率,通过选取适当的并行级别,我们可以得到满足需要的DWT分解元件。具体介绍见下面2部分。
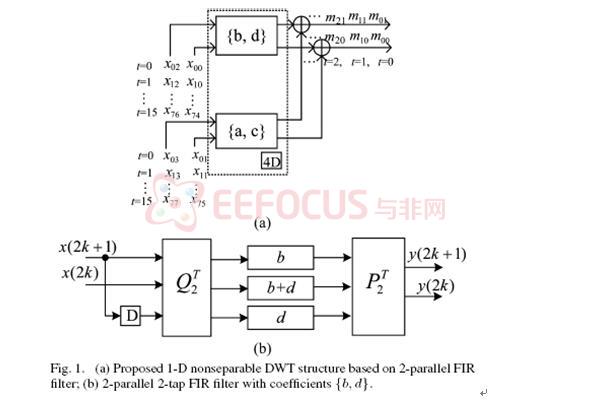
5.3.1 基于并行FIR滤波器的1-D DWT结构
为了便于说明问题,假设滤波器的长度为4,初始图像大小为NxN=8x8。低通滤波器:H={a,b,c,d}; 高通滤波器:G={e,f,g,h};原始图像
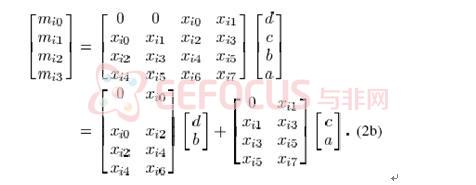
首先在行方向通过低通滤波器,并进行下抽样,得到(2)式
从(2)式中可以简化得到(2a)式
该式可以转换成矩阵形式,并可变换为(2b)式
从(2b)式,我们看到1-D DWT(2a)已经转换成2个只有原始滤波器一半长度的FIR滤波器。
当对(2b)式使用2输入FIR结构,对于
的计算只需要2个时钟周期,首先得到
,接着得到
。对(1)式的行滤波可以用如图1所示的滤波器结构实现。
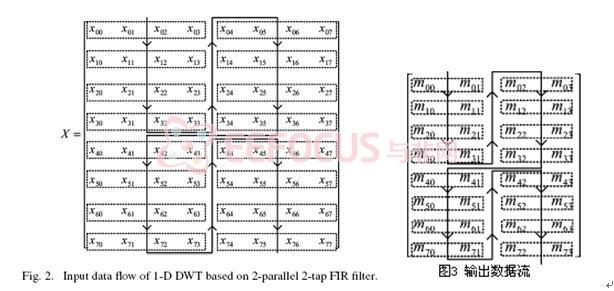
以上结构所需要的硬件资源为3个乘法器,4个加法器和1个延时元件。输入数据流见图2所示,对应的输出数据流见图3所示(即mij输出)
从数据流中可以看出,图1(b)中的每个D要用4D代替。
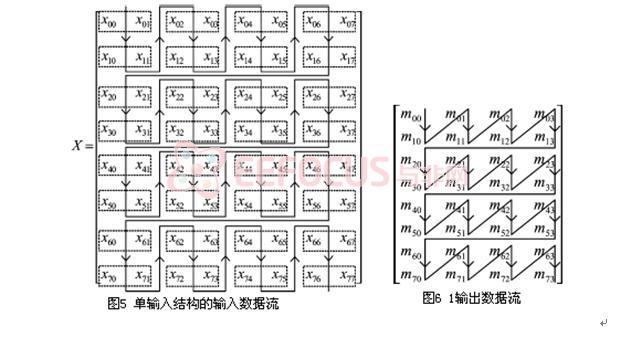
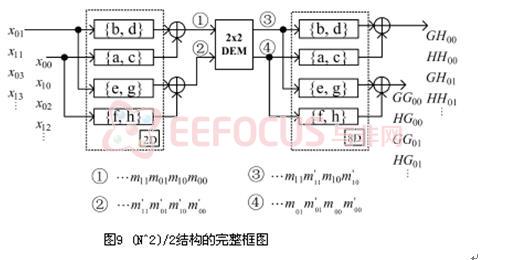
5.3.2 2-D DWT结构(N2/2结构)
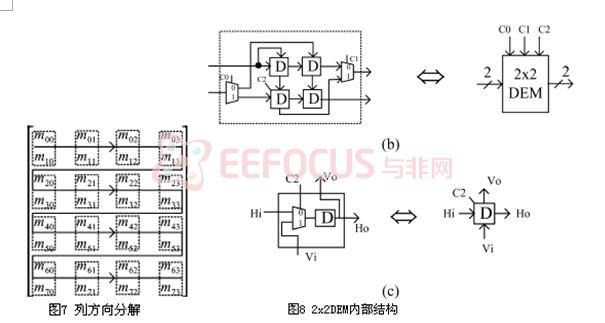
使用1输入的FIR滤波器代替之前的2输入滤波器我们可以得到N2/2速率的结构。其对应的数据流如图5和图6所示。进一步,可以进行列方向的分解,具体过程如同行方向分解,如图7所示。但若将行和列部分同步起来,还存在一个问题,可以从数据流中看出,例如计算出m00和m10需要2个周期,而列分解需同时处理m00和m10。要在N2/2个时钟周期内完成该分辨率级分解,还需要一个DEM元件,即Delay Element Matrix,其内部结构如图8。
最终我们得到了进行一级分解的完整结构如图9
若进行多级小波分解,还需要缓存HH子带的数据,并进行同样过程的处理。
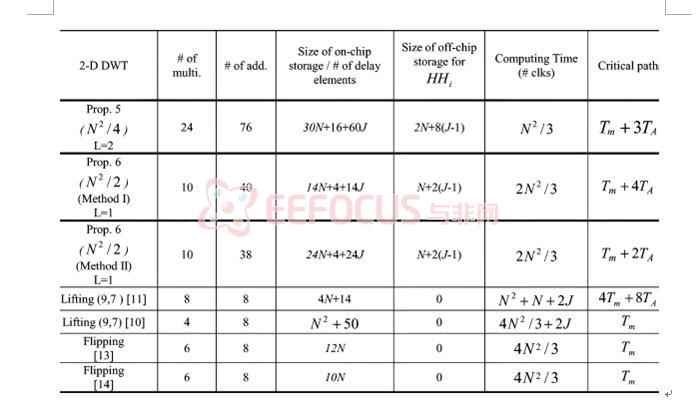
利用此算法,我们可以轻易的扩展到JPEG2000编码器中所使用的9/7和5/3小波的硬件结构,该结构在计算速率上有着很大的优势,同时也会在资源使用上耗费更多的资源,但硬件资源的耗费可以控制在一个合理的范围内。一个9/7小波算法实现的技术参数比较见下表:
|
|






 雷达卡
雷达卡
 发表于 2015-4-27 08:09:08
发表于 2015-4-27 08:09:08

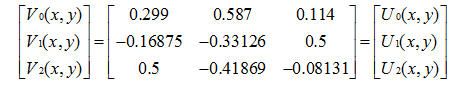
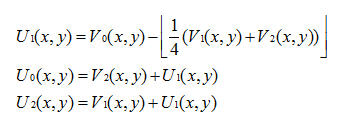

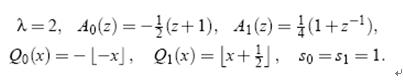

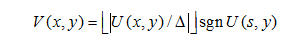


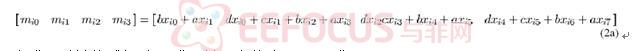

 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 微信
微信 收藏
收藏 分享
分享 支持
支持 反对
反对 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 抢沙发
抢沙发 千斤顶
千斤顶 显身卡
显身卡