|
|
14.8 变量类型
ARM C编译器支持基本的数据类型:char、short、int、long long、float和double。表14.2说明了armcc对C语言所使用的数据类型的映射。
表14.2 C编译器数据类型映射
C数据类型
| 表示的意义
| char
| 无符号8位字节数据
| short
| 有符号16位半字数据
| int
| 有符号32位字数据
| long
| 有符号32位字数据
| long long
| 有符号64位双字数据
|
ARM指令集中,无论是数据处理指令还是数据加载/存储指令,处理的数据类型不同,指令的执行效率是不一样的。本章将详细讨论,如何在程序中为变量分配合理的数据类型,来提高代码的执行效率。
14.8.1 局部变量
ARM属于RISC的体系结构,所有大多数的数据处理都是在32位的寄存器中进行的。基于这个原因,局部变量应尽可能使用32位数据类型int或long。
| 注意
| 一些情况下不得不使用char或short类型,例如要使用char或short类型的数据溢出指令时归零特性时,如模运算255+1=0,就要使用char类型。
|
为了说明局部变量类型的影响,先来看一个简单的例子。
char charinc (char a)
{
return a + 1;
}
编译出的结果如下。
charinc
ADD a1,a1,#1
AND a1,a1,#&ff
MOV pc,lr
再把上面的程序段中变量a声明位int型,代码如下。
int wordinc (int a)
{
return a + 1;
}
比较一下编译器输出结果。
wordinc
ADD a1,a1,#1
MOV pc,lr
分析上面的两段代码不难发现,当把变量声明为char型时,编译器增加了额外的ADD指令来保证其范围在0~255之间。
14.8.2 有符号数和无符号数
上一节讨论了对于局部变量和函数参数,使用int型比使用char或short型要好。本节将对程序中的有符号整数(signed int)和无符号整数(unsigned int)的执行效率进行分析比较。
首先来看上一节的例子,如果将变量指定为有符号的半字类型(编译器默认short型为有符号类型),程序的源代码如下。
short shortinc (short a)
{
return a + 1;
}
编译后的结果如下。
shortinc
ADD a1,a1,#1
MOV a1,a1,LSL #16
MOV a1,a1,ASR #16
MOV pc,lr
分析发现,该结果比使用int型的变量多增加了两条指令(LSL和ASR)。编译器先将变量左移16位,然后右移16位,以实现一个16位符号扩展。右移是符号位扩展移位,它复制了符号位来填充高16位。
通常情况下,如果程序中只有加法、减法和乘法,那么有符号和无符号数的执行效率相差不大。但是,如果有了除法,情况就不一样了。详细内容可参加除法运算优化一节。
14.8.3 全局变量
1.边界对齐
对于RISC体系结构的处理器来说,访问边界对齐的数据要比访问非对齐的数据更高效。表14.3显示了ARM结构下各数据类型所占的字节数。
表14.3 各数据类型所占字节数
C数据类型
| 所占字节数
| char,singed char,unsigned char
| 1
| short,unsigned short
| 2
| int,unsigned int,long,unsigned long
| 4
| float
| 4
| double
| 4
| long long
| 4
|
变量定义虽然很简单,但是也有很多值得注意的地方。先看下面的例子。
定义1:
char a;
short b;
char c;
int d;
定义2:
char a;
char c;
short b;
int d;
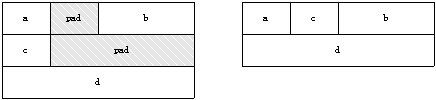
这里定义的4个变量形式都一样,只是次序不同,却导致了在最终映像中不同的数据布局,如同14.1所示,其中pad为无意义的填充数据。
图14.1 变量在数据区里的布局
从图中可以看出,第二种方式节约了更多的存储器空间。
由此可见,在变量声明的时候需要考虑怎样最佳的控制存储器布局。当然,编译器在一定程度上能够优化这类问题,但最好的方法还是在编译的时候把所有相同类型的变量放在一起定义。
2.访问外部变量
首先来看一个例子。下面的例子定义了一些全局变量,在main( )中为这些变量赋值并将其打印输出。
/************
* access.c *
************/
#include <stdio.h>
char tx;
char rx;
char byte;
char c;
unsigned state;
unsigned flags;
int main ()
{ tx = 1;
rx = 2;
byte = 3;
c = 4;
state = 5;
flags = 6;
printf("%u %u %u %u %u %u\n", tx, rx, byte, c, state, flags);
return 0;
}
使用armcc编译,生成的代码大小如下。
C$$code 132
C$$data 12
如果将全局变量声明为extern,变量的定义在其他文件中,那么生成的代码量将有所增加。
将全局变量声明为extern,生成的代码大小如下。
C$$code 168
C$$data 12
这是因为当将变量声明为extern后,每次访问变量编译器都将从内存重新加载,而不是使用内存偏移,直接访问。
下图显示编译器对声明为extern变量的访问。
解决的办法是将要从外部引用的extern变量定义在一个结构体中。在程序中通过结构体访问外部变量。具体用法如下例所示。
/*************
* globals.h *
*************/
/* DECLARATIONS of globals - included in all sources */
#ifdef __arm
struct globs
{ char tx;
char rx;
图14.2 对extern变量的访问
char byte;
char c;
unsigned state;
unsigned flags;
};
extern struct globs g;
#define tx g.tx
#define rx g.rx
#define byte g.byte
#define c g.c
#define state g.state
#define flags g.flags
#else
extern char tx;
extern char rx;
extern char byte;
extern char c;
extern unsigned state;
extern unsigned flags;
#endif
/*************
* globals.c *
*************/
/* DEFINITIONS of globals - single source file */
#ifdef __arm
# include "globals.h"
struct globs g;
#else
char tx;
char rx;
char byte;
char c;
unsigned state;
unsigned flags;
#endif
/************
* access.c *
************/
#include <stdio.h>
#include "globals.h"
int main ()
{tx = 1;
rx = 2;
byte = 3;
c = 4;
state = 5;
flags = 6;
printf("%u %u %u %u %u %u\n", tx, rx, byte, c, state, flags);
return 0;
}
将变量定义在结构体内有以下几点好处。
· 全局变量使用更小的内存空间。(没有使用结构体占有24字节,而使用结构体之后只占有12字节)
· 全局变量被放置在ZI段而不是RW段,这样就减少了ROM映像文件的大小。 |
|






 雷达卡
雷达卡
 发表于 2014-10-10 07:23:40
发表于 2014-10-10 07:23:40


 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 微信
微信 收藏
收藏 分享
分享 支持
支持 反对
反对 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 抢沙发
抢沙发 千斤顶
千斤顶 显身卡
显身卡