|
2528| 0
|



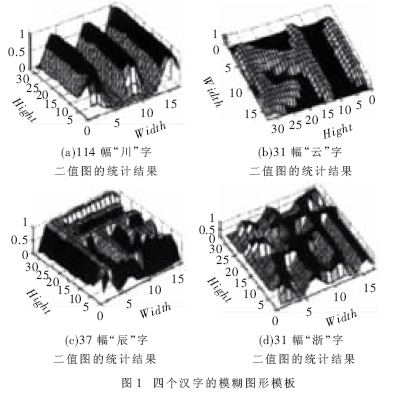
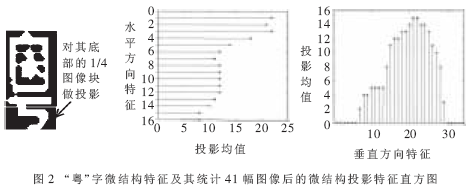
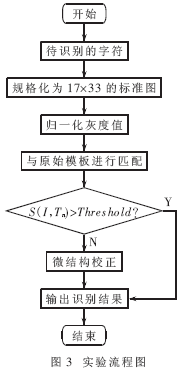
[待整理] 一种基于模糊模板匹配的车牌汉字识别方法 |
小黑屋|文字版|手机版|DIY编程器网 ( 桂ICP备14005565号-1 )
GMT+8, 2026-4-23 22:53 , 耗时 0.140486 秒, 21 个查询请求 , Gzip 开启.
各位嘉宾言论仅代表个人观点,非属DIY编程器网立场。

桂公网安备 45031202000115号
本站由桂林市临桂区技兴电子商务经营部独家赞助。旨在技术交流,请自觉遵守国家法律法规,一旦发现将做封号删号处理。


 雷达卡
雷达卡
 发表于 2015-4-27 20:19:08
发表于 2015-4-27 20:19:08


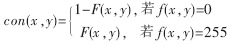

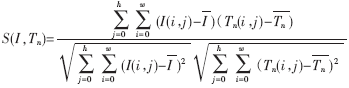
 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 微信
微信 收藏
收藏 分享
分享 支持
支持 反对
反对 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 抢沙发
抢沙发 千斤顶
千斤顶 显身卡
显身卡