|
|
车牌自动识别系统能将输入的汽车图象通过处理识别,输出为几个字节大小的车牌字符串,无论在存储空间的占用上还是与管理数据库相连方面都有无可比拟的优越性。在大型停车场,交通部门的违章监测(电子警察)、高速公路及桥梁的收费站管理等方面,有着广泛的应用前景。
1 车牌定位及预处理
将汽车图象文件以Raw格式文件输入计算机后,计算机将车牌部分从整幅图象中抽取出来,实现车牌定位。设定门限值为127,设定检测阈值为16。然后对图象自上而下逐行扫描,若某一行的0→1和1→0变化次数大于该阈值则假设其为待测车牌最低点,继续逐行扫描直至0→1和1→0变化次数小于8的情况出现。将该值假设为待测车牌最高点。若最高点与最低点之差大于15则认为目标已检测到,否则继续进行扫描。如果未检测到符合上述条件的目标,则自动调整门限值重复以上的操作。直到找到目标为止。
利用二值图象在竖直方向上的投影作为特征,从左至右寻找目标的中心点坐标。考察以前所得的目标高度作为边长的方形窗口内的竖直方向投影之和(即所包含的象素值为1的象素点的个数),若该值小于经验阈值(经多次试验该阈值取为150)则视为无文字信息的背景部分,若该值首次大于阈值则视为待识车牌的左边界部分;之后,若当投影和首次由大变小时跳出循环,则取该窗口的中点横坐标为目标中心点。以目标中心点为基准向右,以高度为所得目标高度、宽度为30的窗口再次统计象素值为1的象素点个数,若该值首次小于经验阈值16则视为已到目标右边界,并取该点坐标为目标最右点的坐标。对目标最左点坐标的确定同理可得。
由于车牌的高宽比固定,将之作为一种目标评定标准,考虑变形因素,若高宽比不处于区间(0.2~0.6)之内则视为无效目标,修正门限值后开始循环,最终达到边界。
目标图象预处理包括图象平滑、字符与背景的分离、范围调整和倾斜修正等。
根据实际情况,图象的平滑采用八邻域平均法。所用的掩模为:

实现字符与背景分离所采用的门限化算法是:在有256个元素的一维整型数数组元素A中存放目标图象中所有灰度值为i的象素点个数。比较得到在目标图象中具有最大概率的灰度值a 。研究发现有以下两种不同的情况,分别如图1和图2所示。
对情况一,图象信息主要位于灰度区间(0~a)之间,此时再找出灰度区间(0~b),使该区间内象素点个数占目标图象总象素点个数的30%。取b为门限值,使灰度值大于该门限值的象素点取值为0,其他情况的象素点取值为1。对情况二同理处理。从左至右用与目标图象等高且宽度为30的检测窗口扫描目标图象。考察其象素密度,当值为1的象素点个数小于50%时停止扫描。取此时检测窗口的左坐标为目标的左边界。目标的右边界同理可得。根据所得车牌图象的范围信息,在有必要的情况下,用旋转变换进行倾斜修正。
2 自动单字符列切分
列切分是把定位后提取出的牌照图象,切分成单个的字符图象。字符块在垂直方向上的投影必然在正确的分割位置上(即字符或字符内的间隙处)取得了局部最小值,且这个位置应该满足书写规则和字符尺寸限制。对字符图象进行垂直方向的投影。在水平方向上从左至右检测各坐标的投影数值。检测到第一个投影值不为0的坐标可视为首字符的左边界,从该坐标向右检测到的第一个投影值为0的坐标可视为首字符的右边界,其余字符的边界坐标同理可得。
通过字符的平均字宽和两字符左边界之间的平均距离去除可能存在的误分。对于字宽小于平均字宽一定比例(如0.2)的字符视为无效字符;前后两字符距离小于平均距离且此距离与字宽之和不大于平均距离,则合并之为一个字符;对于字宽大于平均字宽一定比例(如2.4)则视为两字符出现粘连。
经过上述处理可以得到准确的切分结果。将字符变换到64×64的点阵空间上,以方便进行后续特征抽取等阶段的处理。
3 轮廓化与细化
轮廓化处理采用四邻域法,对噪声平滑后的64×64的文字图象f(i,j),扫描黑象素点(i,j)的上、下、左、右四个邻点,只要有一点不为黑,则点(i,j)为字符轮廓上的点,置其灰度为1(即黑色),其他情况均令点(i,j)的灰度为0(即白色)。细化处理采用二次扫描细化法,该方法的速度较快,但由于是一种较为简单的迭代算法,有时会造成一定程度的骨架形变。
图3(b)和图3(c)分别给出轮廓化和细化处理后的结果。
4 微结构特征的提取
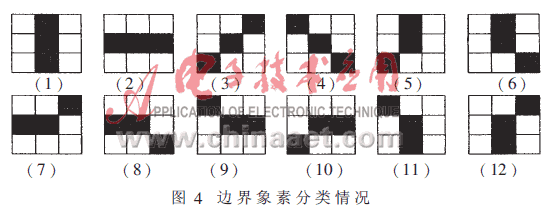
把字符分割成n×n的网络,对每个小网络统计出区域笔划的方向特征。每个小区域突出字符的局部特征,且对微小的偏移或变形不敏感。把相邻三点形成的两条线素定义为微结构。轮廓化后的字符,其中有十二种边界线素的情况和字符笔划相关(如图4所示)。
根据字符笔划的四个基本方向,可以相应定义水平、垂直、±45°四种线素方向。并可以统计出区域笔划方向密度向量。
把64×64的待识字符划分为5×5的网格,前4×4的网格大小为13×13,最后一行、一列网格除最后一个为12×12外,最后一行为12×13,最后一列为13×12,统计其笔划方向特征矢量,这样就在每个区域上得到一个水平、垂直、+45°、-45°的四维方向特征,组成了整个字符的100维分类特征。
所抽取特征的稳定性对识别的正确率至关重要,故在细分类中对字符进行8×8和7×7的二重分割。分别统计这64+49=113个小区域的区域笔划方向向量(共有四个方向),组成113×4=452维的细分类特征。采用8×8的分割是为了在更小的区域内抽取更精细的结构特征。为了防止分割边缘的不稳定,进行了7×7的二重分割,使原来最不稳定的8×8网格边缘的笔划处于7×7网格的中央最稳定区域,提高了区域边缘笔划的稳定性。
5 匹配策略
为了提高识别的准确和速度,在匹配中采用多级分类的识别方案。
粗分类中,采用单纯的区域笔划方向特征,把字符分成5×5的网格(共25个小区域)分别统计线素的四个方向特性,构成100维(25×4)的特征向量。采用绝对值距离判别准则。设字典库中的任一特征向量为Pji=(pj1,pj2,pj3,pj4,Λ,pj100),待识字符的特征向量为h=(h1,h2,h3,h4,Λ,h100),字典中的任意一个模板与待识字符之间的距离为dj。
在dj中选取值最小的前10个字符作为初步匹配的结果,进入下一步进行细分类。
在细分类中,对候选字符通过二重分割提取452维的特征矢量作为细分类的特征。用与粗分类类似的判别准则进行第二次匹配。通过试验确定参数,用不同的权值系数与粗分类准则结合起来决定待识字符与不同标准模板的匹配程度,取前四个作为最终结果并将其输出到指定的文本文件之中。
6 标准字典库的建立
字库是在众多字库中择优选取的。其中汉字从宋体字库中选取,字母及数字从OCR-A字库中选取。对标准字符分别进行归一化、轮廓化和特征抽取,标准模板就是从中抽取特征得到的特征向量。
7 试验结果
车牌定位非常理想;字符分割无误;对汉字首字符的识别有时会出现误识(可见汉字的识别难度较大,匹配算法和模板库的建立方面是问题的关键所在);对字母及数字的识别较好;在细分类优先级的前两级达到100%。 |
|






 雷达卡
雷达卡
 发表于 2015-4-27 23:00:39
发表于 2015-4-27 23:00:39

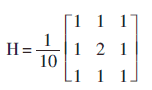


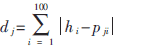
 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 微信
微信 收藏
收藏 分享
分享 支持
支持 反对
反对 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 抢沙发
抢沙发 千斤顶
千斤顶 显身卡
显身卡